 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Synthetic Images To Uncover Population Biases In Facial Landmarks Detection
Paper and Code
Nov 01, 2021
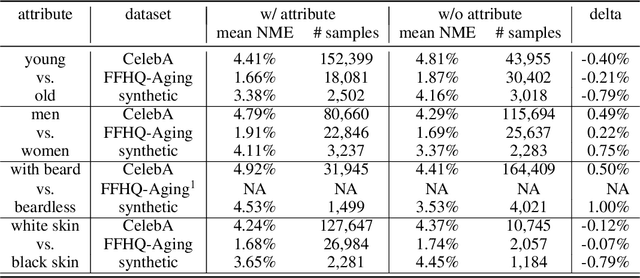
In order to analyze a trained model performance and identify its weak spots, one has to set aside a portion of the data for testing. The test set has to be large enough to detect statistically significant biases with respect to all the relevant sub-groups in the target population. This requirement may be difficult to satisfy, especially in data-hungry applications. We propose to overcome this difficulty by generating synthetic test set. We use the face landmarks detection task to validate our proposal by showing that all the biases observed on real datasets are also seen on a carefully designed synthetic dataset. This shows that synthetic test sets can efficiently detect a model's weak spots and overcome limitations of real test set in terms of quantity and/or diversity.