 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexar Dashcam Collision Prediction Dataset and Challenge
Mar 05, 2025This paper presents the Nexar Dashcam Collision Prediction Dataset and Challenge, designed to support research in traffic event analysis, collision prediction, and autonomous vehicle safety. The dataset consists of 1,500 annotated video clips, each approximately 40 seconds long, capturing a diverse range of real-world traffic scenarios. Videos are labeled with event type (collision/near-collision vs. normal driving), environmental conditions (lighting conditions and weather), and scene type (urban, rural, highway, etc.). For collision and near-collision cases, additional temporal labels are provided, including the precise moment of the event and the alert time, marking when the collision first becomes predictable. To advance research on accident prediction, we introduce the Nexar Dashcam Collision Prediction Challenge, a public competition on top of this dataset. Participants are tasked with developing machine learning models that predict the likelihood of an imminent collision, given an input video. Model performance is evaluated using the average precision (AP) computed across multiple intervals before the accident (i.e. 500 ms, 1000 ms, and 1500 ms prior to the event), emphasizing the importance of early and reliable predictions. The dataset is released under an open license with restrictions on unethical use, ensuring responsible research and innovation.
Face Recognition Using Synthetic Face Data
May 17, 2023



In the field of deep learning applied to face recognition, securing large-scale, high-quality datasets is vital for attaining precise and reliable results. However, amassing significant volumes of high-quality real data faces hurdles such as time limitations, financial burdens, and privacy issues. Furthermore, prevalent datasets are often impaired by racial biases and annotation inaccuracies. In this paper, we underscore the promising application of synthetic data, generated through rendering digital faces via our computer graphics pipeline, in achieving competitive results with the state-of-the-art on synthetic data across multiple benchmark datasets. By finetuning the model,we obtain results that rival those achieved when training with hundreds of thousands of real images (98.7% on LFW [1]). We further investigate the contribution of adding intra-class variance factors (e.g., makeup, accessories, haircuts) on model performance. Finally, we reveal the sensitivity of pre-trained face recognition models to alternating specific parts of the face by leveraging the granular control capability in our platform.
Knowing the Distance: Understanding the Gap Between Synthetic and Real Data For Face Parsing
Mar 27, 2023
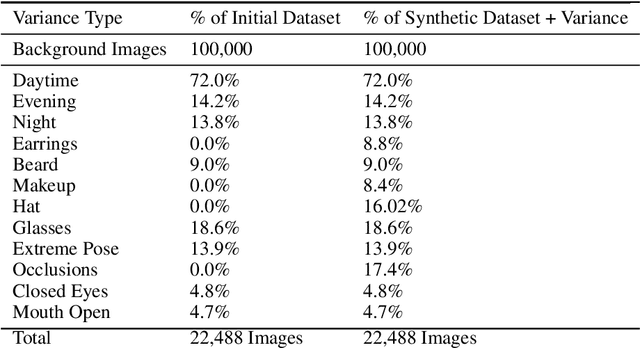

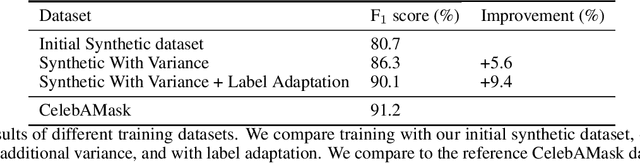
The use of synthetic data for training computer vision algorithms has become increasingly popular due to its cost-effectiveness, scalability, and ability to provide accurate multi-modality labels. Although recent studies have demonstrated impressive results when training networks solely on synthetic data, there remains a performance gap between synthetic and real data that is commonly attributed to lack of photorealism. The aim of this study is to investigate the gap in greater detail for the face parsing task. We differentiate between three types of gaps: distribution gap, label gap, and photorealism gap. Our findings show that the distribution gap is the largest contributor to the performance gap, accounting for over 50% of the gap. By addressing this gap and accounting for the labels gap, we demonstrate that a model trained on synthetic data achieves comparable results to one trained on a similar amount of real data. This suggests that synthetic data is a viable alternative to real data, especially when real data is limited or difficult to obtain. Our study highlights the importance of content diversity in synthetic datasets and challenges the notion that the photorealism gap is the most critical factor affecting the performance of computer vision models trained on synthetic data.
Hands-Up: Leveraging Synthetic Data for Hands-On-Wheel Detection
May 31, 2022
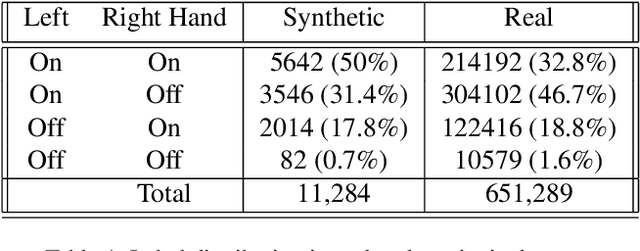

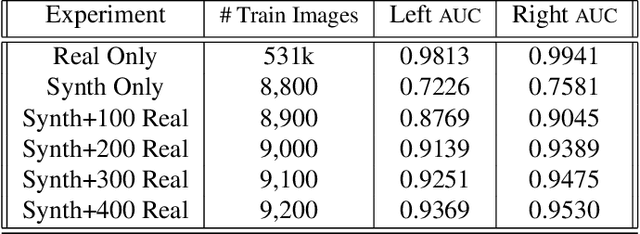
Over the past few years there has been major progress in the field of synthetic data generation using simulation based techniques. These methods use high-end graphics engines and physics-based ray-tracing rendering in order to represent the world in 3D and create highly realistic images. Datagen has specialized in the generation of high-quality 3D humans, realistic 3D environments and generation of realistic human motion. This technology has been developed into a data generation platform which we used for these experiments. This work demonstrates the use of synthetic photo-realistic in-cabin data to train a Driver Monitoring System that uses a lightweight neural network to detect whether the driver's hands are on the wheel. We demonstrate that when only a small amount of real data is available, synthetic data can be a simple way to boost performance. Moreover, we adopt the data-centric approach and show how performing error analysis and generating the missing edge-cases in our platform boosts performance. This showcases the ability of human-centric synthetic data to generalize well to the real world, and help train algorithms in computer vision settings where data from the target domain is scarce or hard to collect.