 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Recognition Using Synthetic Face Data
May 17, 2023In the field of deep learning applied to face recognition, securing large-scale, high-quality datasets is vital for attaining precise and reliable results. However, amassing significant volumes of high-quality real data faces hurdles such as time limitations, financial burdens, and privacy issues. Furthermore, prevalent datasets are often impaired by racial biases and annotation inaccuracies. In this paper, we underscore the promising application of synthetic data, generated through rendering digital faces via our computer graphics pipeline, in achieving competitive results with the state-of-the-art on synthetic data across multiple benchmark datasets. By finetuning the model,we obtain results that rival those achieved when training with hundreds of thousands of real images (98.7% on LFW [1]). We further investigate the contribution of adding intra-class variance factors (e.g., makeup, accessories, haircuts) on model performance. Finally, we reveal the sensitivity of pre-trained face recognition models to alternating specific parts of the face by leveraging the granular control capability in our platform.
Knowing the Distance: Understanding the Gap Between Synthetic and Real Data For Face Parsing
Mar 27, 2023
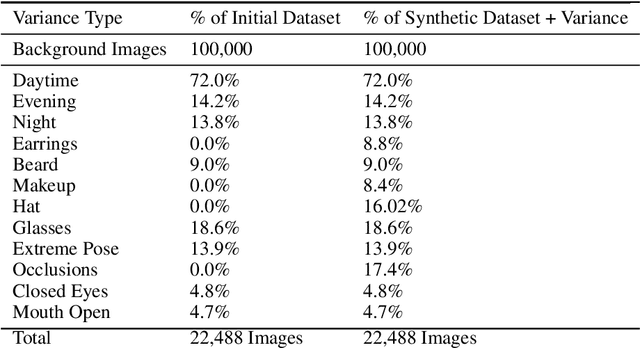

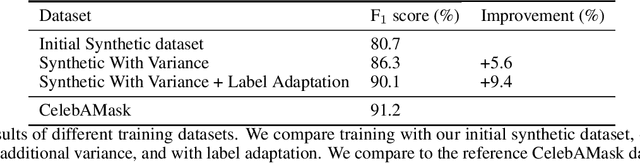
The use of synthetic data for training computer vision algorithms has become increasingly popular due to its cost-effectiveness, scalability, and ability to provide accurate multi-modality labels. Although recent studies have demonstrated impressive results when training networks solely on synthetic data, there remains a performance gap between synthetic and real data that is commonly attributed to lack of photorealism. The aim of this study is to investigate the gap in greater detail for the face parsing task. We differentiate between three types of gaps: distribution gap, label gap, and photorealism gap. Our findings show that the distribution gap is the largest contributor to the performance gap, accounting for over 50% of the gap. By addressing this gap and accounting for the labels gap, we demonstrate that a model trained on synthetic data achieves comparable results to one trained on a similar amount of real data. This suggests that synthetic data is a viable alternative to real data, especially when real data is limited or difficult to obtain. Our study highlights the importance of content diversity in synthetic datasets and challenges the notion that the photorealism gap is the most critical factor affecting the performance of computer vision models trained on synthetic data.
Visual navigation for airborne control of ground robots from tethered platform: creation of the first prototype
Jan 05, 2019
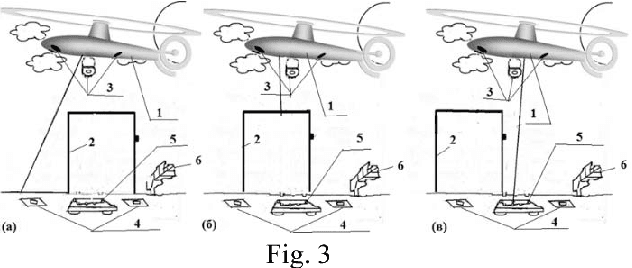


We propose control systems for the coordination of the ground robots. We develop robot efficient coordination using the devices located on towers or a tethered aerial apparatus tracing the robots on controlled area and supervising their environment including natural and artificial markings. The simple prototype of such a system was created in the Laboratory of Applied Mathematics of Ariel University (under the supervision of Prof. Domoshnitsky Alexander) in collaboration with company TRANSIST VIDEO LLC (Skolkovo, Moscow). We plan to create much more complicated prototype using Kamin grant (Israel)
* 11 pages, 7 figures