 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNexar Dashcam Collision Prediction Dataset and Challenge
Mar 05, 2025This paper presents the Nexar Dashcam Collision Prediction Dataset and Challenge, designed to support research in traffic event analysis, collision prediction, and autonomous vehicle safety. The dataset consists of 1,500 annotated video clips, each approximately 40 seconds long, capturing a diverse range of real-world traffic scenarios. Videos are labeled with event type (collision/near-collision vs. normal driving), environmental conditions (lighting conditions and weather), and scene type (urban, rural, highway, etc.). For collision and near-collision cases, additional temporal labels are provided, including the precise moment of the event and the alert time, marking when the collision first becomes predictable. To advance research on accident prediction, we introduce the Nexar Dashcam Collision Prediction Challenge, a public competition on top of this dataset. Participants are tasked with developing machine learning models that predict the likelihood of an imminent collision, given an input video. Model performance is evaluated using the average precision (AP) computed across multiple intervals before the accident (i.e. 500 ms, 1000 ms, and 1500 ms prior to the event), emphasizing the importance of early and reliable predictions. The dataset is released under an open license with restrictions on unethical use, ensuring responsible research and innovation.
Neural Relighting with Subsurface Scattering by Learning the Radiance Transfer Gradient
Jun 15, 2023Reconstructing and relighting objects and scenes under varying lighting conditions is challenging: existing neural rendering methods often cannot handle the complex interactions between materials and light. Incorporating pre-computed radiance transfer techniques enables global illumination, but still struggles with materials with subsurface scattering effects. We propose a novel framework for learning the radiance transfer field via volume rendering and utilizing various appearance cues to refine geometry end-to-end. This framework extends relighting and reconstruction capabilities to handle a wider range of materials in a data-driven fashion. The resulting models produce plausible rendering results in existing and novel conditions. We will release our code and a novel light stage dataset of objects with subsurface scattering effects publicly available.
Voxel-informed Language Grounding
May 19, 2022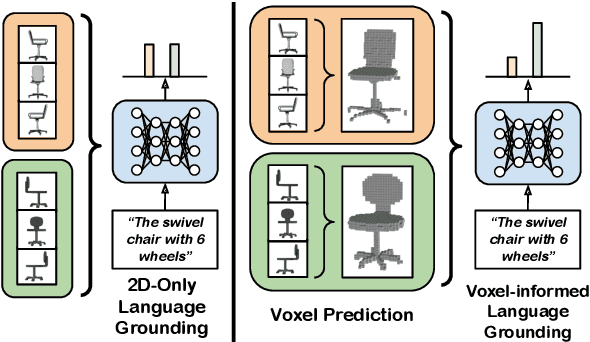
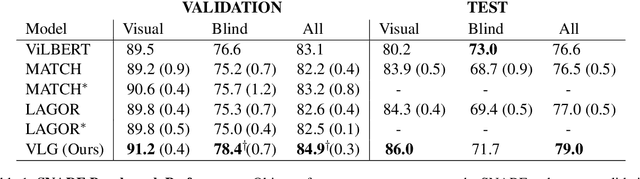
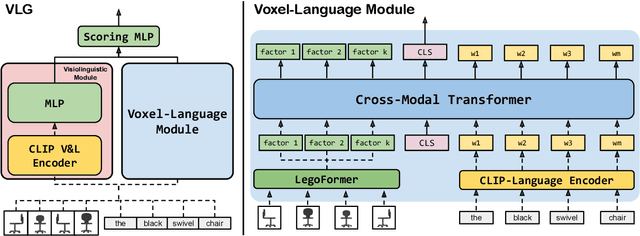
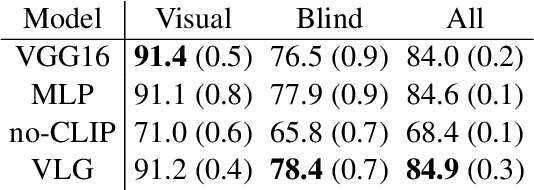
Natural language applied to natural 2D images describes a fundamentally 3D world. We present the Voxel-informed Language Grounder (VLG), a language grounding model that leverages 3D geometric information in the form of voxel maps derived from the visual input using a volumetric reconstruction model. We show that VLG significantly improves grounding accuracy on SNARE, an object reference game task. At the time of writing, VLG holds the top place on the SNARE leaderboard, achieving SOTA results with a 2.0% absolute improvement.
Be Your Own Prada: Fashion Synthesis with Structural Coherence
Oct 19, 2017
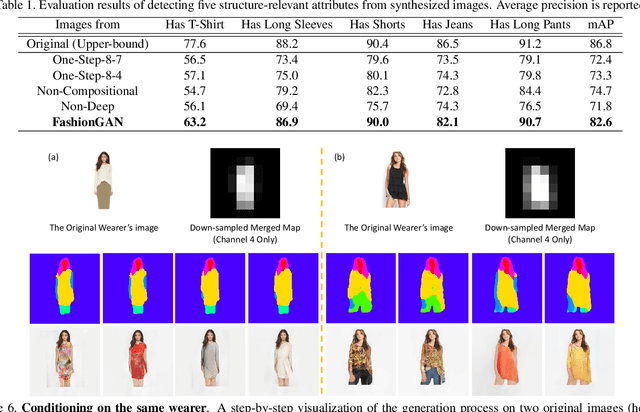


We present a novel and effective approach for generating new clothing on a wearer through generative adversarial learning. Given an input image of a person and a sentence describing a different outfit, our model "redresses" the person as desired, while at the same time keeping the wearer and her/his pose unchanged. Generating new outfits with precise regions conforming to a language description while retaining wearer's body structure is a new challenging task. Existing generative adversarial networks are not ideal in ensuring global coherence of structure given both the input photograph and language description as conditions. We address this challenge by decomposing the complex generative process into two conditional stages. In the first stage, we generate a plausible semantic segmentation map that obeys the wearer's pose as a latent spatial arrangement. An effective spatial constraint is formulated to guide the generation of this semantic segmentation map. In the second stage, a generative model with a newly proposed compositional mapping layer is used to render the final image with precise regions and textures conditioned on this map. We extended the DeepFashion dataset [8] by collecting sentence descriptions for 79K images. We demonstrate the effectiveness of our approach through both quantitative and qualitative evaluations. A user study is also conducted. The codes and the data are available at http://mmlab.ie.cuhk. edu.hk/projects/FashionGAN/.
Deep Cascaded Bi-Network for Face Hallucination
Jul 18, 2016
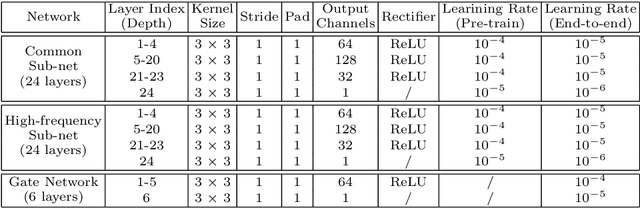

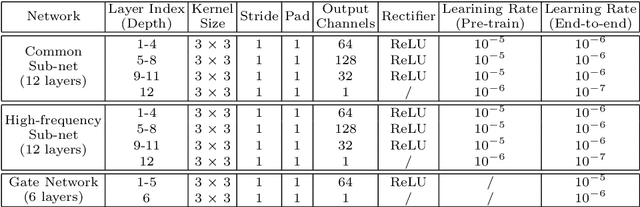
We present a novel framework for hallucinating faces of unconstrained poses and with very low resolution (face size as small as 5pxIOD). In contrast to existing studies that mostly ignore or assume pre-aligned face spatial configuration (e.g. facial landmarks localization or dense correspondence field), we alternatingly optimize two complementary tasks, namely face hallucination and dense correspondence field estimation, in a unified framework. In addition, we propose a new gated deep bi-network that contains two functionality-specialized branches to recover different levels of texture details. Extensive experiments demonstrate that such formulation allows exceptional hallucination quality on in-the-wild low-res faces with significant pose and illumination variations.
Towards Arbitrary-View Face Alignment by Recommendation Trees
Nov 20, 2015
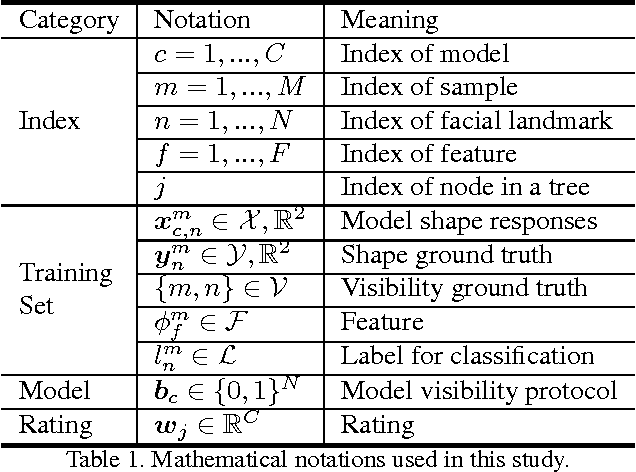
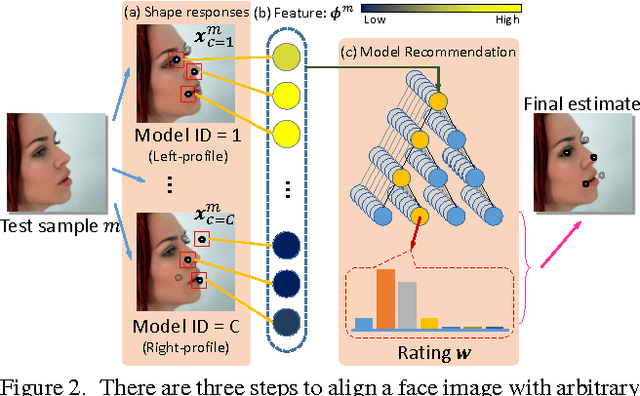

Learning to simultaneously handle face alignment of arbitrary views, e.g. frontal and profile views, appears to be more challenging than we thought. The difficulties lay in i) accommodating the complex appearance-shape relations exhibited in different views, and ii) encompassing the varying landmark point sets due to self-occlusion and different landmark protocols. Most existing studies approach this problem via training multiple viewpoint-specific models, and conduct head pose estimation for model selection. This solution is intuitive but the performance is highly susceptible to inaccurate head pose estimation. In this study, we address this shortcoming through learning an Ensemble of Model Recommendation Trees (EMRT), which is capable of selecting optimal model configuration without prior head pose estimation. The unified framework seamlessly handles different viewpoints and landmark protocols, and it is trained by optimising directly on landmark locations, thus yielding superior results on arbitrary-view face alignment. This is the first study that performs face alignment on the full AFLWdataset with faces of different views including profile view. State-of-the-art performances are also reported on MultiPIE and AFW datasets containing both frontaland profile-view faces.
Transferring Landmark Annotations for Cross-Dataset Face Alignment
Sep 02, 2014

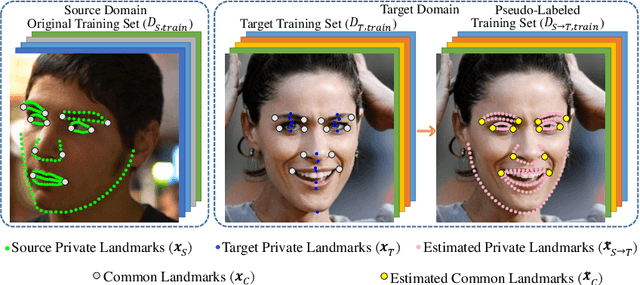

Dataset bias is a well known problem in object recognition domain. This issue, nonetheless, is rarely explored in face alignment research. In this study, we show that dataset plays an integral part of face alignment performance. Specifically, owing to face alignment dataset bias, training on one database and testing on another or unseen domain would lead to poor performance. Creating an unbiased dataset through combining various existing databases, however, is non-trivial as one has to exhaustively re-label the landmarks for standardisation. In this work, we propose a simple and yet effective method to bridge the disparate annotation spaces between databases, making datasets fusion possible. We show extensive results on combining various popular databases (LFW, AFLW, LFPW, HELEN) for improved cross-dataset and unseen data alignment.