 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Landmark Annotations for Cross-Dataset Face Alignment
Paper and Code
Sep 02, 2014

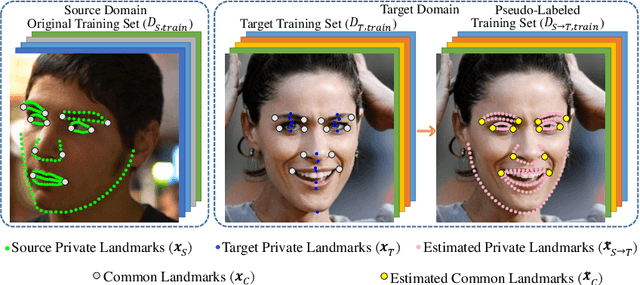

Dataset bias is a well known problem in object recognition domain. This issue, nonetheless, is rarely explored in face alignment research. In this study, we show that dataset plays an integral part of face alignment performance. Specifically, owing to face alignment dataset bias, training on one database and testing on another or unseen domain would lead to poor performance. Creating an unbiased dataset through combining various existing databases, however, is non-trivial as one has to exhaustively re-label the landmarks for standardisation. In this work, we propose a simple and yet effective method to bridge the disparate annotation spaces between databases, making datasets fusion possible. We show extensive results on combining various popular databases (LFW, AFLW, LFPW, HELEN) for improved cross-dataset and unseen data alignment.