 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Arbitrary-View Face Alignment by Recommendation Trees
Paper and Code
Nov 20, 2015
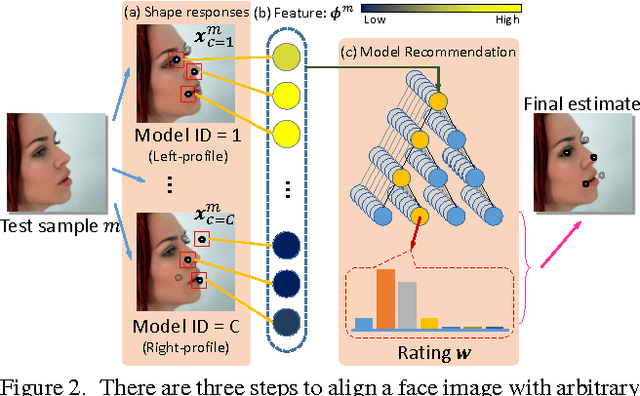

Learning to simultaneously handle face alignment of arbitrary views, e.g. frontal and profile views, appears to be more challenging than we thought. The difficulties lay in i) accommodating the complex appearance-shape relations exhibited in different views, and ii) encompassing the varying landmark point sets due to self-occlusion and different landmark protocols. Most existing studies approach this problem via training multiple viewpoint-specific models, and conduct head pose estimation for model selection. This solution is intuitive but the performance is highly susceptible to inaccurate head pose estimation. In this study, we address this shortcoming through learning an Ensemble of Model Recommendation Trees (EMRT), which is capable of selecting optimal model configuration without prior head pose estimation. The unified framework seamlessly handles different viewpoints and landmark protocols, and it is trained by optimising directly on landmark locations, thus yielding superior results on arbitrary-view face alignment. This is the first study that performs face alignment on the full AFLWdataset with faces of different views including profile view. State-of-the-art performances are also reported on MultiPIE and AFW datasets containing both frontaland profile-view faces.