 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vehicle-in-the-Loop Simulator with AI-Powered Digital Twins for Testing Automated Driving Controllers
Jul 03, 2025Simulators are useful tools for testing automated driving controllers. Vehicle-in-the-loop (ViL) tests and digital twins (DTs) are widely used simulation technologies to facilitate the smooth deployment of controllers to physical vehicles. However, conventional ViL tests rely on full-size vehicles, requiring large space and high expenses. Also, physical-model-based DT suffers from the reality gap caused by modeling imprecision. This paper develops a comprehensive and practical simulator for testing automated driving controllers enhanced by scaled physical cars and AI-powered DT models. The scaled cars allow for saving space and expenses of simulation tests. The AI-powered DT models ensure superior simulation fidelity. Moreover, the simulator integrates well with off-the-shelf software and control algorithms, making it easy to extend. We use a filtered control benchmark with formal safety guarantees to showcase the capability of the simulator in validating automated driving controllers. Experimental studies are performed to showcase the efficacy of the simulator, implying its great potential in validating control solutions for autonomous vehicles and intelligent traffic.
Risk-Aware Autonomous Driving for Linear Temporal Logic Specifications
Sep 15, 2024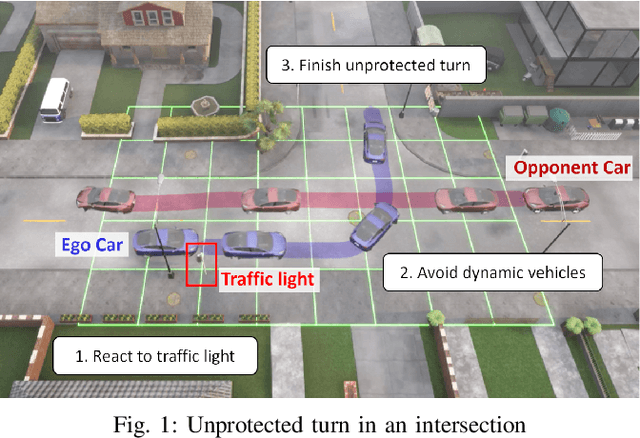
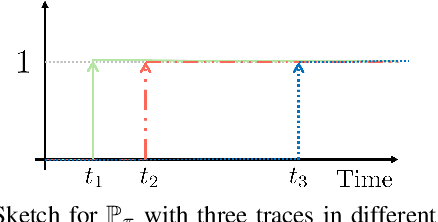
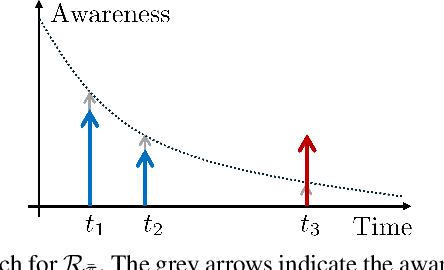

Decision-making for autonomous driving incorporating different types of risks is a challenging topic. This paper proposes a novel risk metric to facilitate the driving task specified by linear temporal logic (LTL) by balancing the risk brought up by different uncertain events. Such a balance is achieved by discounting the costs of these uncertain events according to their timing and severity, thereby reflecting a human-like awareness of risk. We have established a connection between this risk metric and the occupation measure, a fundamental concept in stochastic reachability problems, such that a risk-aware control synthesis problem under LTL specifications is formulated for autonomous vehicles using occupation measures. As a result, the synthesized policy achieves balanced decisions across different types of risks with associated costs, showcasing advantageous versatility and generalizability. The effectiveness and scalability of the proposed approach are validated by three typical traffic scenarios in Carla simulator.
VernaCopter: Disambiguated Natural-Language-Driven Robot via Formal Specifications
Sep 14, 2024



It has been an ambition of many to control a robot for a complex task using natural language (NL). The rise of large language models (LLMs) makes it closer to coming true. However, an LLM-powered system still suffers from the ambiguity inherent in an NL and the uncertainty brought up by LLMs. This paper proposes a novel LLM-based robot motion planner, named \textit{VernaCopter}, with signal temporal logic (STL) specifications serving as a bridge between NL commands and specific task objectives. The rigorous and abstract nature of formal specifications allows the planner to generate high-quality and highly consistent paths to guide the motion control of a robot. Compared to a conventional NL-prompting-based planner, the proposed VernaCopter planner is more stable and reliable due to less ambiguous uncertainty. Its efficacy and advantage have been validated by two small but challenging experimental scenarios, implying its potential in designing NL-driven robots.
Incorporating Target Vehicle Trajectories Predicted by Deep Learning Into Model Predictive Controlled Vehicles
Oct 04, 2023Model Predictive Control (MPC) has been widely applied to the motion planning of autonomous vehicles. An MPC-controlled vehicle is required to predict its own trajectories in a finite prediction horizon according to its model. Beyond this, the vehicle should also incorporate the prediction of the trajectory of its nearby vehicles, or target vehicles (TVs) into its decision-making. The conventional trajectory prediction methods, such as the constant-speed-based ones, are too trivial to accurately capture the potential collision risks. In this report, we propose a novel MPC-based motion planning method for an autonomous vehicle with a set of risk-aware constraints. These constraints incorporate the predicted trajectory of a TV learned using a deep-learning-based method. A recurrent neural network (RNN) is used to predict the TV's future trajectory based on its historical data. Then, the predicted TV trajectory is incorporated into the optimization of the MPC of the ego vehicle to generate collision-free motion. Simulation studies are conducted to showcase the prediction accuracy of the RNN model and the collision-free trajectories generated by the MPC.
Identifying Reaction-Aware Driving Styles of Stochastic Model Predictive Controlled Vehicles by Inverse Reinforcement Learning
Aug 23, 2023



The driving style of an Autonomous Vehicle (AV) refers to how it behaves and interacts with other AVs. In a multi-vehicle autonomous driving system, an AV capable of identifying the driving styles of its nearby AVs can reliably evaluate the risk of collisions and make more reasonable driving decisions. However, there has not been a consistent definition of driving styles for an AV in the literature, although it is considered that the driving style is encoded in the AV's trajectories and can be identified using Maximum Entropy Inverse Reinforcement Learning (ME-IRL) methods as a cost function. Nevertheless, an important indicator of the driving style, i.e., how an AV reacts to its nearby AVs, is not fully incorporated in the feature design of previous ME-IRL methods. In this paper, we describe the driving style as a cost function of a series of weighted features. We design additional novel features to capture the AV's reaction-aware characteristics. Then, we identify the driving styles from the demonstration trajectories generated by the Stochastic Model Predictive Control (SMPC) using a modified ME-IRL method with our newly proposed features. The proposed method is validated using MATLAB simulation and an off-the-shelf experiment.
Using Implicit Behavior Cloning and Dynamic Movement Primitive to Facilitate Reinforcement Learning for Robot Motion Planning
Jul 29, 2023



Reinforcement learning (RL) for motion planning of multi-degree-of-freedom robots still suffers from low efficiency in terms of slow training speed and poor generalizability. In this paper, we propose a novel RL-based robot motion planning framework that uses implicit behavior cloning (IBC) and dynamic movement primitive (DMP) to improve the training speed and generalizability of an off-policy RL agent. IBC utilizes human demonstration data to leverage the training speed of RL, and DMP serves as a heuristic model that transfers motion planning into a simpler planning space. To support this, we also create a human demonstration dataset using a pick-and-place experiment that can be used for similar studies. Comparison studies in simulation reveal the advantage of the proposed method over the conventional RL agents with faster training speed and higher scores. A real-robot experiment indicates the applicability of the proposed method to a simple assembly task. Our work provides a novel perspective on using motion primitives and human demonstration to leverage the performance of RL for robot applications.
Risk-Aware Reward Shaping of Reinforcement Learning Agents for Autonomous Driving
Jun 05, 2023Reinforcement learning (RL) is an effective approach to motion planning in autonomous driving, where an optimal driving policy can be automatically learned using the interaction data with the environment. Nevertheless, the reward function for an RL agent, which is significant to its performance, is challenging to be determined. The conventional work mainly focuses on rewarding safe driving states but does not incorporate the awareness of risky driving behaviors of the vehicles. In this paper, we investigate how to use risk-aware reward shaping to leverage the training and test performance of RL agents in autonomous driving. Based on the essential requirements that prescribe the safety specifications for general autonomous driving in practice, we propose additional reshaped reward terms that encourage exploration and penalize risky driving behaviors. A simulation study in OpenAI Gym indicates the advantage of risk-aware reward shaping for various RL agents. Also, we point out that proximal policy optimization (PPO) is likely to be the best RL method that works with risk-aware reward shaping.
Exploiting Symmetry and Heuristic Demonstrations in Off-policy Reinforcement Learning for Robotic Manipulation
Apr 12, 2023



Reinforcement learning demonstrates significant potential in automatically building control policies in numerous domains, but shows low efficiency when applied to robot manipulation tasks due to the curse of dimensionality. To facilitate the learning of such tasks, prior knowledge or heuristics that incorporate inherent simplification can effectively improve the learning performance. This paper aims to define and incorporate the natural symmetry present in physical robotic environments. Then, sample-efficient policies are trained by exploiting the expert demonstrations in symmetrical environments through an amalgamation of reinforcement and behavior cloning, which gives the off-policy learning process a diverse yet compact initiation. Furthermore, it presents a rigorous framework for a recent concept and explores its scope for robot manipulation tasks. The proposed method is validated via two point-to-point reaching tasks of an industrial arm, with and without an obstacle, in a simulation experiment study. A PID controller, which tracks the linear joint-space trajectories with hard-coded temporal logic to produce interim midpoints, is used to generate demonstrations in the study. The results of the study present the effect of the number of demonstrations and quantify the magnitude of behavior cloning to exemplify the possible improvement of model-free reinforcement learning in common manipulation tasks. A comparison study between the proposed method and a traditional off-policy reinforcement learning algorithm indicates its advantage in learning performance and potential value for applications.
Human-Robot Skill Transfer with Enhanced Compliance via Dynamic Movement Primitives
Apr 12, 2023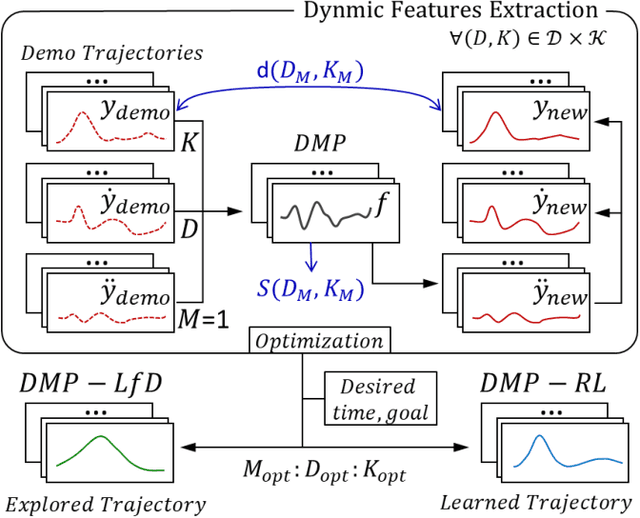
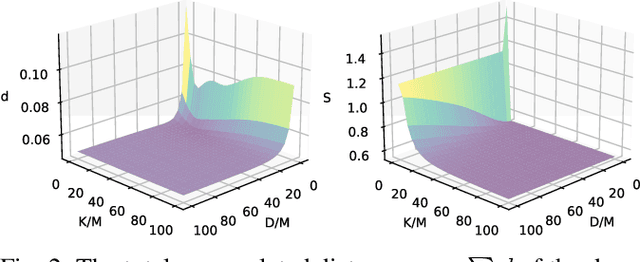
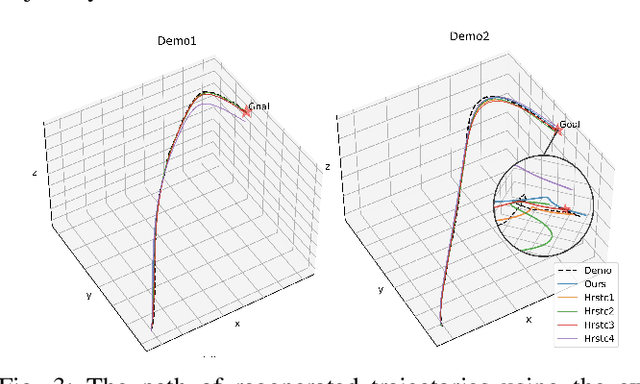
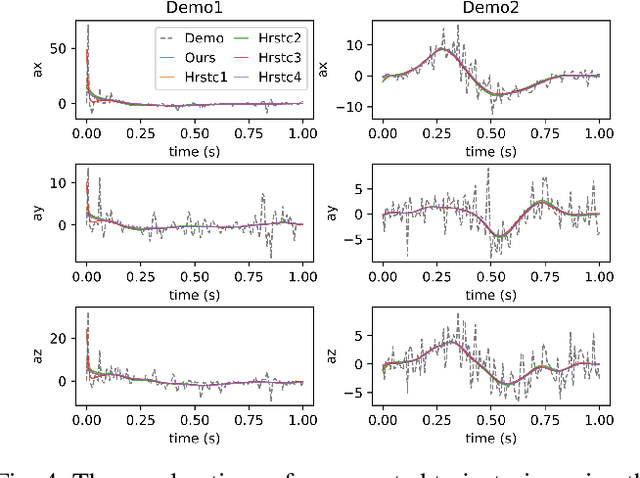
Finding an efficient way to adapt robot trajectory is a priority to improve overall performance of robots. One approach for trajectory planning is through transferring human-like skills to robots by Learning from Demonstrations (LfD). The human demonstration is considered the target motion to mimic. However, human motion is typically optimal for human embodiment but not for robots because of the differences between human biomechanics and robot dynamics. The Dynamic Movement Primitives (DMP) framework is a viable solution for this limitation of LfD, but it requires tuning the second-order dynamics in the formulation. Our contribution is introducing a systematic method to extract the dynamic features from human demonstration to auto-tune the parameters in the DMP framework. In addition to its use with LfD, another utility of the proposed method is that it can readily be used in conjunction with Reinforcement Learning (RL) for robot training. In this way, the extracted features facilitate the transfer of human skills by allowing the robot to explore the possible trajectories more efficiently and increasing robot compliance significantly. We introduced a methodology to extract the dynamic features from multiple trajectories based on the optimization of human-likeness and similarity in the parametric space. Our method was implemented into an actual human-robot setup to extract human dynamic features and used to regenerate the robot trajectories following both LfD and RL with DMP. It resulted in a stable performance of the robot, maintaining a high degree of human-likeness based on accumulated distance error as good as the best heuristic tuning.
Distributed Coverage Control of Constrained Constant-Speed Unicycle Multi-Agent Systems
Apr 12, 2023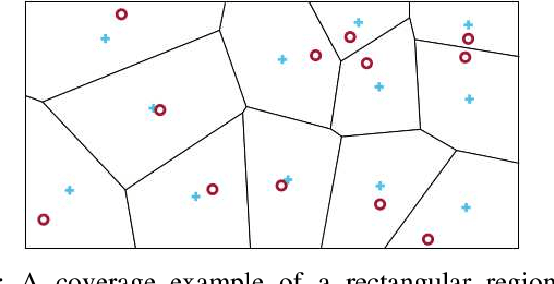
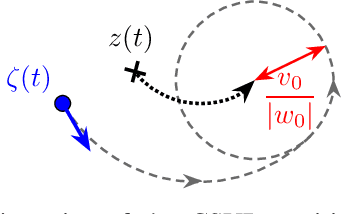
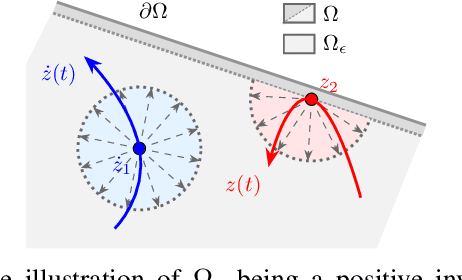
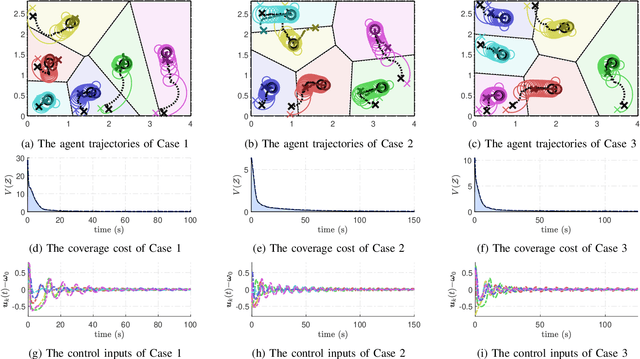
This paper proposes a novel distributed coverage controller for a multi-agent system with constant-speed unicycle robots (CSUR). The work is motivated by the limitation of the conventional method that does not ensure the satisfaction of hard state- and input-dependent constraints and leads to feasibility issues for multi-CSUR systems. In this paper, we solve these problems by designing a novel coverage cost function and a saturated gradient-search-based control law. Invariant set theory and Lyapunov-based techniques are used to prove the state-dependent confinement and the convergence of the system state to the optimal coverage configuration, respectively. The controller is implemented in a distributed manner based on a novel communication standard among the agents. A series of simulation case studies are conducted to validate the effectiveness of the proposed coverage controller in different initial conditions and with control parameters. A comparison study in simulation reveals the advantage of the proposed method in terms of avoiding infeasibility. The experiment study verifies the applicability of the method to real robots with uncertainties. The development procedure of the method from theoretical analysis to experimental validation provides a novel framework for multi-agent system coordinate control with complex agent dynamics.