 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Target Vehicle Trajectories Predicted by Deep Learning Into Model Predictive Controlled Vehicles
Oct 04, 2023Model Predictive Control (MPC) has been widely applied to the motion planning of autonomous vehicles. An MPC-controlled vehicle is required to predict its own trajectories in a finite prediction horizon according to its model. Beyond this, the vehicle should also incorporate the prediction of the trajectory of its nearby vehicles, or target vehicles (TVs) into its decision-making. The conventional trajectory prediction methods, such as the constant-speed-based ones, are too trivial to accurately capture the potential collision risks. In this report, we propose a novel MPC-based motion planning method for an autonomous vehicle with a set of risk-aware constraints. These constraints incorporate the predicted trajectory of a TV learned using a deep-learning-based method. A recurrent neural network (RNN) is used to predict the TV's future trajectory based on its historical data. Then, the predicted TV trajectory is incorporated into the optimization of the MPC of the ego vehicle to generate collision-free motion. Simulation studies are conducted to showcase the prediction accuracy of the RNN model and the collision-free trajectories generated by the MPC.
Identifying Reaction-Aware Driving Styles of Stochastic Model Predictive Controlled Vehicles by Inverse Reinforcement Learning
Aug 23, 2023



The driving style of an Autonomous Vehicle (AV) refers to how it behaves and interacts with other AVs. In a multi-vehicle autonomous driving system, an AV capable of identifying the driving styles of its nearby AVs can reliably evaluate the risk of collisions and make more reasonable driving decisions. However, there has not been a consistent definition of driving styles for an AV in the literature, although it is considered that the driving style is encoded in the AV's trajectories and can be identified using Maximum Entropy Inverse Reinforcement Learning (ME-IRL) methods as a cost function. Nevertheless, an important indicator of the driving style, i.e., how an AV reacts to its nearby AVs, is not fully incorporated in the feature design of previous ME-IRL methods. In this paper, we describe the driving style as a cost function of a series of weighted features. We design additional novel features to capture the AV's reaction-aware characteristics. Then, we identify the driving styles from the demonstration trajectories generated by the Stochastic Model Predictive Control (SMPC) using a modified ME-IRL method with our newly proposed features. The proposed method is validated using MATLAB simulation and an off-the-shelf experiment.
Data Generation Method for Learning a Low-dimensional Safe Region in Safe Reinforcement Learning
Sep 10, 2021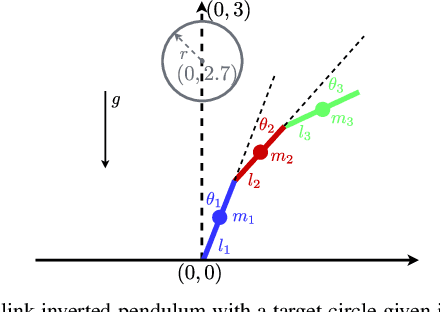
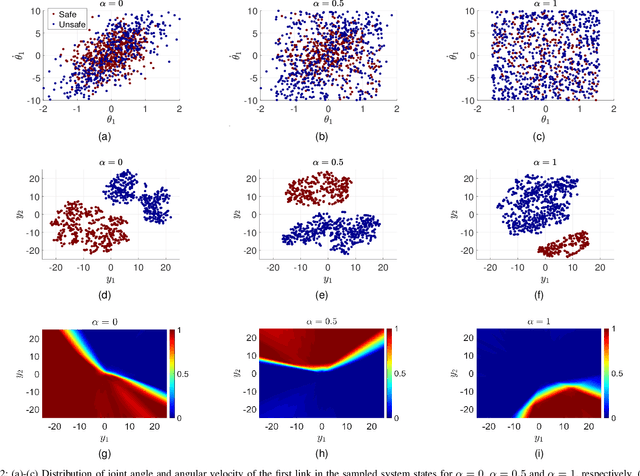
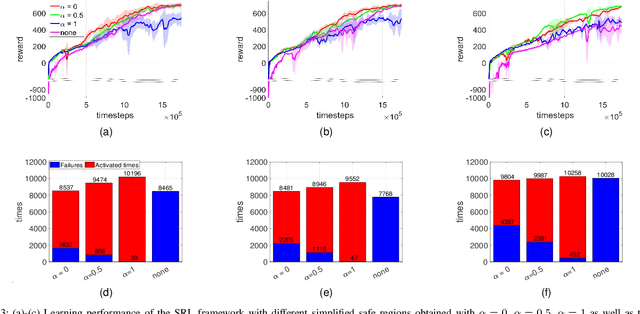
Safe reinforcement learning aims to learn a control policy while ensuring that neither the system nor the environment gets damaged during the learning process. For implementing safe reinforcement learning on highly nonlinear and high-dimensional dynamical systems, one possible approach is to find a low-dimensional safe region via data-driven feature extraction methods, which provides safety estimates to the learning algorithm. As the reliability of the learned safety estimates is data-dependent, we investigate in this work how different training data will affect the safe reinforcement learning approach. By balancing between the learning performance and the risk of being unsafe, a data generation method that combines two sampling methods is proposed to generate representative training data. The performance of the method is demonstrated with a three-link inverted pendulum example.
Gaussian Process-based Stochastic Model Predictive Control for Overtaking in Autonomous Racing
May 25, 2021

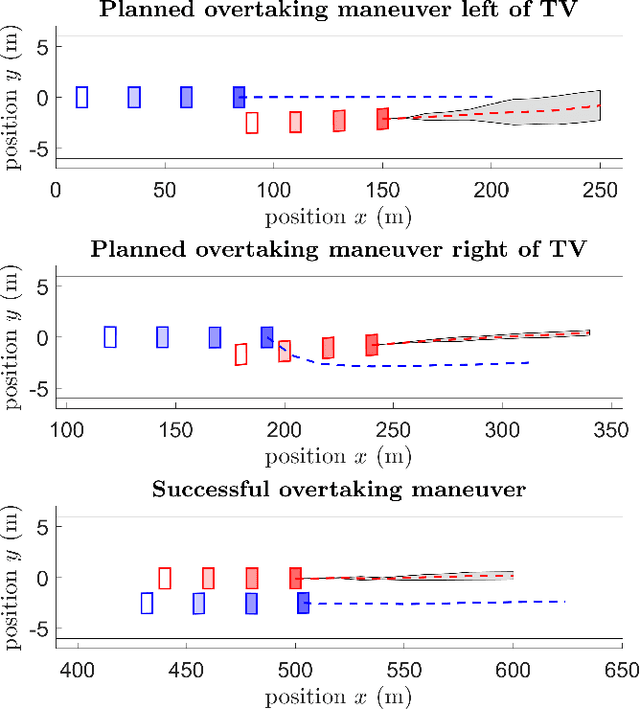
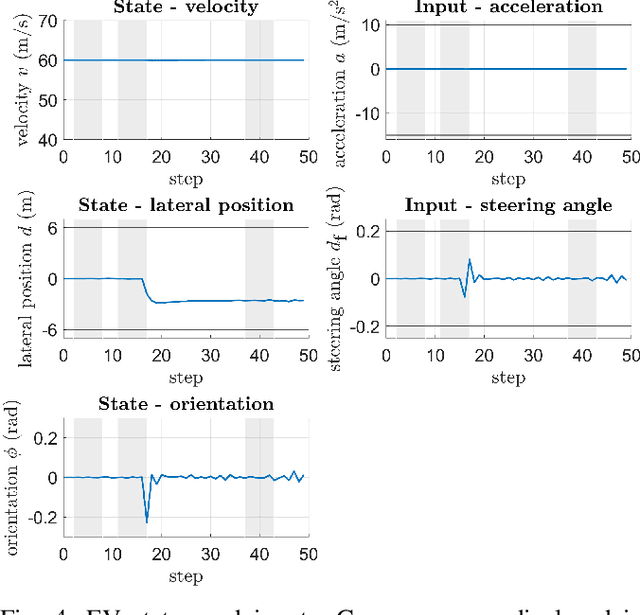
A fundamental aspect of racing is overtaking other race cars. Whereas previous research on autonomous racing has majorly focused on lap-time optimization, here, we propose a method to plan overtaking maneuvers in autonomous racing. A Gaussian process is used to learn the behavior of the leading vehicle. Based on the outputs of the Gaussian process, a stochastic Model Predictive Control algorithm plans optimistic trajectories, such that the controlled autonomous race car is able to overtake the leading vehicle. The proposed method is tested in a simple simulation scenario.
Learning a Low-dimensional Representation of a Safe Region for Safe Reinforcement Learning on Dynamical Systems
Oct 19, 2020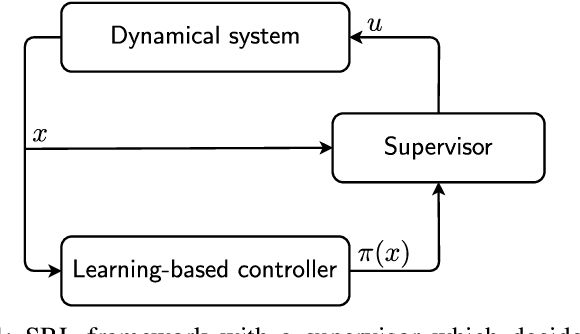


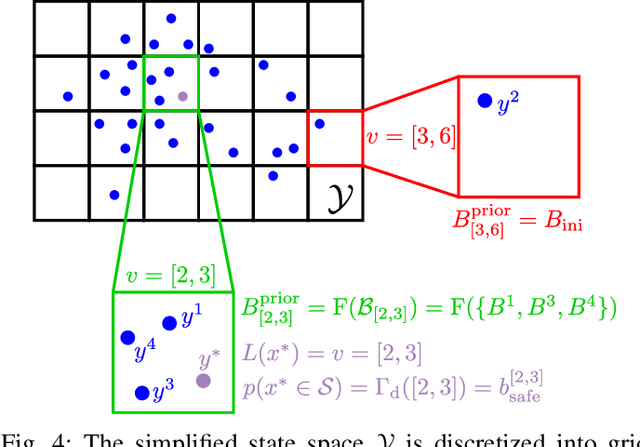
For safely applying reinforcement learning algorithms on high-dimensional nonlinear dynamical systems, a simplified system model is used to formulate a safe reinforcement learning framework. Based on the simplified system model, a low-dimensional representation of the safe region is identified and is used to provide safety estimates for learning algorithms. However, finding a satisfying simplified system model for complex dynamical systems usually requires a considerable amount of effort. To overcome this limitation, we propose in this work a general data-driven approach that is able to efficiently learn a low-dimensional representation of the safe region. Through an online adaptation method, the low-dimensional representation is updated by using the feedback data such that more accurate safety estimates are obtained. The performance of the proposed approach for identifying the low-dimensional representation of the safe region is demonstrated with a quadcopter example. The results show that, compared to previous work, a more reliable and representative low-dimensional representation of the safe region is derived, which then extends the applicability of the safe reinforcement learning framework.