 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Space Constrained Learning with Modality Decoupling for Multimodal Object Detection
Nov 19, 2025



Multimodal object detection has attracted significant attention in both academia and industry for its enhanced robustness. Although numerous studies have focused on improving modality fusion strategies, most neglect fusion degradation, and none provide a theoretical analysis of its underlying causes. To fill this gap, this paper presents a systematic theoretical investigation of fusion degradation in multimodal detection and identifies two key optimization deficiencies: (1) the gradients of unimodal branch backbones are severely suppressed under multimodal architectures, resulting in under-optimization of the unimodal branches; (2) disparities in modality quality cause weaker modalities to experience stronger gradient suppression, which in turn results in imbalanced modality learning. To address these issues, this paper proposes a Representation Space Constrained Learning with Modality Decoupling (RSC-MD) method, which consists of two modules. The RSC module and the MD module are designed to respectively amplify the suppressed gradients and eliminate inter-modality coupling interference as well as modality imbalance, thereby enabling the comprehensive optimization of each modality-specific backbone. Extensive experiments conducted on the FLIR, LLVIP, M3FD, and MFAD datasets demonstrate that the proposed method effectively alleviates fusion degradation and achieves state-of-the-art performance across multiple benchmarks. The code and training procedures will be released at https://github.com/yikangshao/RSC-MD.
Streamlining Biomedical Research with Specialized LLMs
Apr 15, 2025In this paper, we propose a novel system that integrates state-of-the-art, domain-specific large language models with advanced information retrieval techniques to deliver comprehensive and context-aware responses. Our approach facilitates seamless interaction among diverse components, enabling cross-validation of outputs to produce accurate, high-quality responses enriched with relevant data, images, tables, and other modalities. We demonstrate the system's capability to enhance response precision by leveraging a robust question-answering model, significantly improving the quality of dialogue generation. The system provides an accessible platform for real-time, high-fidelity interactions, allowing users to benefit from efficient human-computer interaction, precise retrieval, and simultaneous access to a wide range of literature and data. This dramatically improves the research efficiency of professionals in the biomedical and pharmaceutical domains and facilitates faster, more informed decision-making throughout the R\&D process. Furthermore, the system proposed in this paper is available at https://synapse-chat.patsnap.com.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

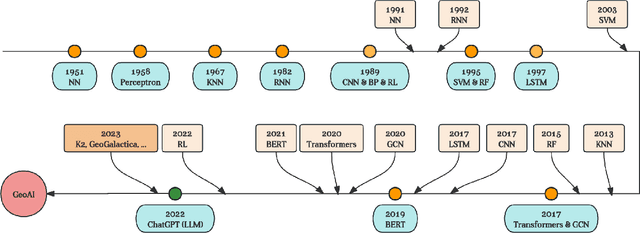
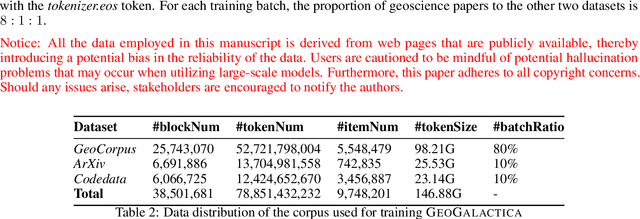
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
Exploring Iterative Refinement with Diffusion Models for Video Grounding
Oct 26, 2023



Video grounding aims to localize the target moment in an untrimmed video corresponding to a given sentence query. Existing methods typically select the best prediction from a set of predefined proposals or directly regress the target span in a single-shot manner, resulting in the absence of a systematical prediction refinement process. In this paper, we propose DiffusionVG, a novel framework with diffusion models that formulates video grounding as a conditional generation task, where the target span is generated from Gaussian noise inputs and interatively refined in the reverse diffusion process. During training, DiffusionVG progressively adds noise to the target span with a fixed forward diffusion process and learns to recover the target span in the reverse diffusion process. In inference, DiffusionVG can generate the target span from Gaussian noise inputs by the learned reverse diffusion process conditioned on the video-sentence representations. Our DiffusionVG follows the encoder-decoder architecture, which firstly encodes the video-sentence features and iteratively denoises the predicted spans in its specialized span refining decoder. Without bells and whistles, our DiffusionVG demonstrates competitive or even superior performance compared to existing well-crafted models on mainstream Charades-STA and ActivityNet Captions benchmarks.
SSLCL: An Efficient Model-Agnostic Supervised Contrastive Learning Framework for Emotion Recognition in Conversations
Oct 25, 2023



Emotion recognition in conversations (ERC) is a rapidly evolving task within the natural language processing community, which aims to detect the emotions expressed by speakers during a conversation. Recently, a growing number of ERC methods have focused on leveraging supervised contrastive learning (SCL) to enhance the robustness and generalizability of learned features. However, current SCL-based approaches in ERC are impeded by the constraint of large batch sizes and the lack of compatibility with most existing ERC models. To address these challenges, we propose an efficient and model-agnostic SCL framework named Supervised Sample-Label Contrastive Learning with Soft-HGR Maximal Correlation (SSLCL), which eliminates the need for a large batch size and can be seamlessly integrated with existing ERC models without introducing any model-specific assumptions. Specifically, we introduce a novel perspective on utilizing label representations by projecting discrete labels into dense embeddings through a shallow multilayer perceptron, and formulate the training objective to maximize the similarity between sample features and their corresponding ground-truth label embeddings, while minimizing the similarity between sample features and label embeddings of disparate classes. Moreover, we innovatively adopt the Soft-HGR maximal correlation as a measure of similarity between sample features and label embeddings, leading to significant performance improvements over conventional similarity measures. Additionally, multimodal cues of utterances are effectively leveraged by SSLCL as data augmentations to boost model performances. Extensive experiments on two ERC benchmark datasets, IEMOCAP and MELD, demonstrate the compatibility and superiority of our proposed SSLCL framework compared to existing state-of-the-art SCL methods. Our code is available at \url{https://github.com/TaoShi1998/SSLCL}.
Identifying Reaction-Aware Driving Styles of Stochastic Model Predictive Controlled Vehicles by Inverse Reinforcement Learning
Aug 23, 2023



The driving style of an Autonomous Vehicle (AV) refers to how it behaves and interacts with other AVs. In a multi-vehicle autonomous driving system, an AV capable of identifying the driving styles of its nearby AVs can reliably evaluate the risk of collisions and make more reasonable driving decisions. However, there has not been a consistent definition of driving styles for an AV in the literature, although it is considered that the driving style is encoded in the AV's trajectories and can be identified using Maximum Entropy Inverse Reinforcement Learning (ME-IRL) methods as a cost function. Nevertheless, an important indicator of the driving style, i.e., how an AV reacts to its nearby AVs, is not fully incorporated in the feature design of previous ME-IRL methods. In this paper, we describe the driving style as a cost function of a series of weighted features. We design additional novel features to capture the AV's reaction-aware characteristics. Then, we identify the driving styles from the demonstration trajectories generated by the Stochastic Model Predictive Control (SMPC) using a modified ME-IRL method with our newly proposed features. The proposed method is validated using MATLAB simulation and an off-the-shelf experiment.
Scalable Spectral Algorithms for Community Detection in Directed Networks
Sep 23, 2013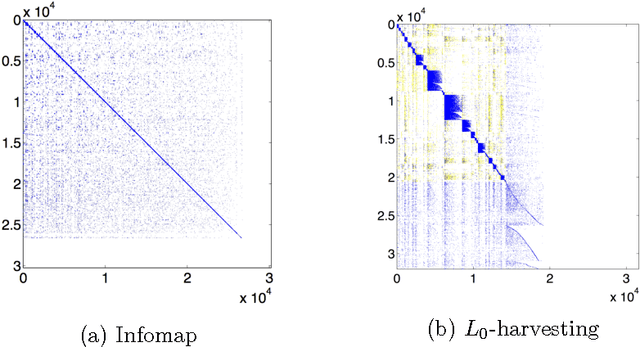
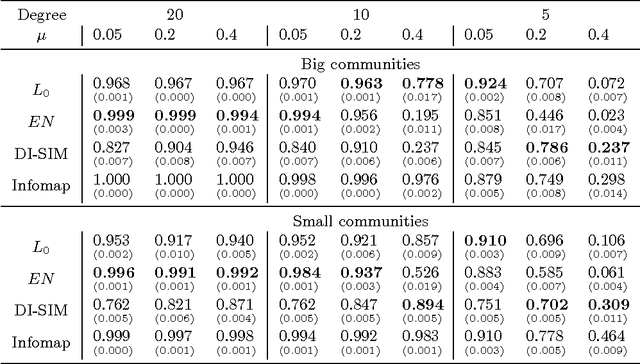
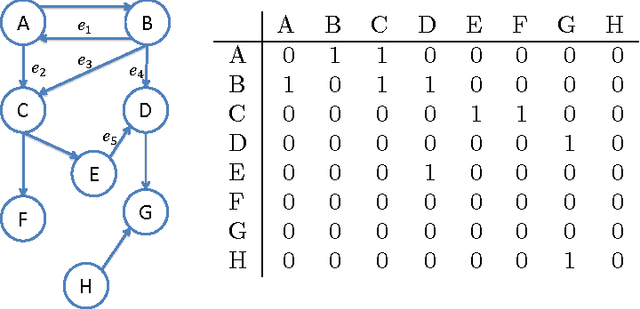
Community detection has been one of the central problems in network studies and directed network is particularly challenging due to asymmetry among its links. In this paper, we found that incorporating the direction of links reveals new perspectives on communities regarding to two different roles, source and terminal, that a node plays in each community. Intriguingly, such communities appear to be connected with unique spectral property of the graph Laplacian of the adjacency matrix and we exploit this connection by using regularized SVD methods. We propose harvesting algorithms, coupled with regularized SVDs, that are linearly scalable for efficient identification of communities in huge directed networks. The proposed algorithm shows great performance and scalability on benchmark networks in simulations and successfully recovers communities in real network applications.
Data spectroscopy: Eigenspaces of convolution operators and clustering
Nov 20, 2009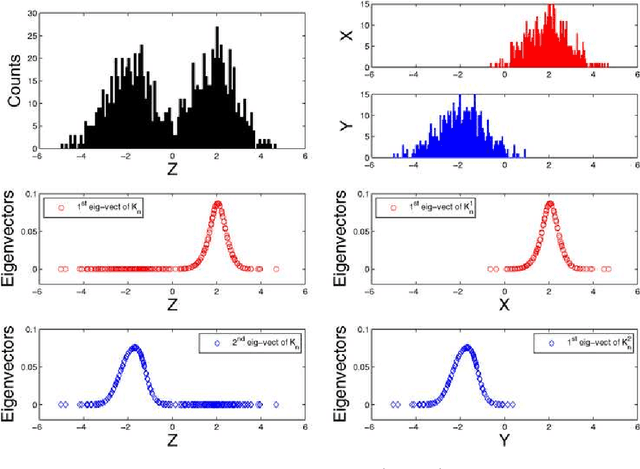
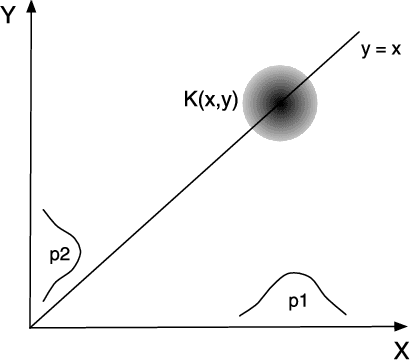

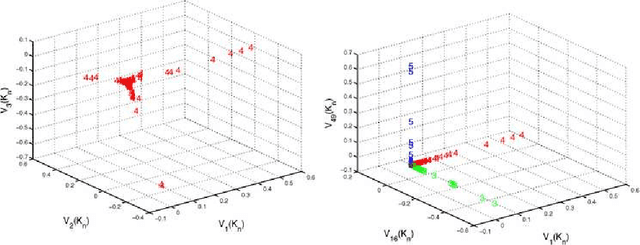
This paper focuses on obtaining clustering information about a distribution from its i.i.d. samples. We develop theoretical results to understand and use clustering information contained in the eigenvectors of data adjacency matrices based on a radial kernel function with a sufficiently fast tail decay. In particular, we provide population analyses to gain insights into which eigenvectors should be used and when the clustering information for the distribution can be recovered from the sample. We learn that a fixed number of top eigenvectors might at the same time contain redundant clustering information and miss relevant clustering information. We use this insight to design the data spectroscopic clustering (DaSpec) algorithm that utilizes properly selected eigenvectors to determine the number of clusters automatically and to group the data accordingly. Our findings extend the intuitions underlying existing spectral techniques such as spectral clustering and Kernel Principal Components Analysis, and provide new understanding into their usability and modes of failure. Simulation studies and experiments on real-world data are conducted to show the potential of our algorithm. In particular, DaSpec is found to handle unbalanced groups and recover clusters of different shapes better than the competing methods.
* Published in at http://dx.doi.org/10.1214/09-AOS700 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)