 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData spectroscopy: Eigenspaces of convolution operators and clustering
Paper and Code
Nov 20, 2009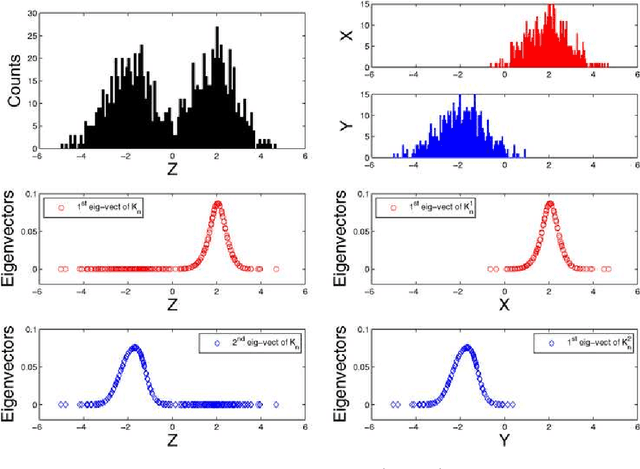
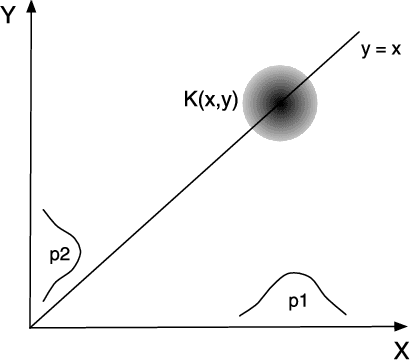

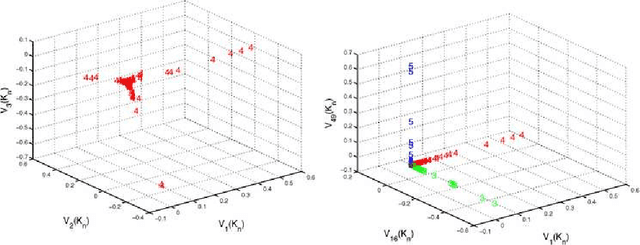
This paper focuses on obtaining clustering information about a distribution from its i.i.d. samples. We develop theoretical results to understand and use clustering information contained in the eigenvectors of data adjacency matrices based on a radial kernel function with a sufficiently fast tail decay. In particular, we provide population analyses to gain insights into which eigenvectors should be used and when the clustering information for the distribution can be recovered from the sample. We learn that a fixed number of top eigenvectors might at the same time contain redundant clustering information and miss relevant clustering information. We use this insight to design the data spectroscopic clustering (DaSpec) algorithm that utilizes properly selected eigenvectors to determine the number of clusters automatically and to group the data accordingly. Our findings extend the intuitions underlying existing spectral techniques such as spectral clustering and Kernel Principal Components Analysis, and provide new understanding into their usability and modes of failure. Simulation studies and experiments on real-world data are conducted to show the potential of our algorithm. In particular, DaSpec is found to handle unbalanced groups and recover clusters of different shapes better than the competing methods.