 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Representation via Action-Free Transformer encoder-decoder for Meta Reinforcement Learning
Dec 17, 2025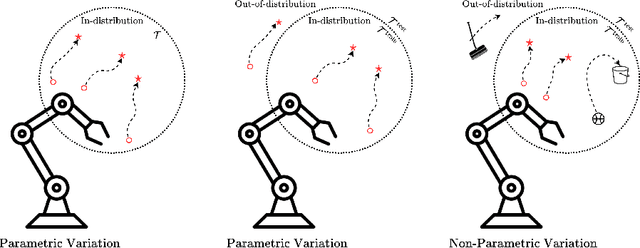



Reinforcement learning (RL) enables robots to operate in uncertain environments, but standard approaches often struggle with poor generalization to unseen tasks. Context-adaptive meta reinforcement learning addresses these limitations by conditioning on the task representation, yet they mostly rely on complete action information in the experience making task inference tightly coupled to a specific policy. This paper introduces Context Representation via Action Free Transformer encoder decoder (CRAFT), a belief model that infers task representations solely from sequences of states and rewards. By removing the dependence on actions, CRAFT decouples task inference from policy optimization, supports modular training, and leverages amortized variational inference for scalable belief updates. Built on a transformer encoder decoder with rotary positional embeddings, the model captures long range temporal dependencies and robustly encodes both parametric and non-parametric task variations. Experiments on the MetaWorld ML-10 robotic manipulation benchmark show that CRAFT achieves faster adaptation, improved generalization, and more effective exploration compared to context adaptive meta--RL baselines. These findings highlight the potential of action-free inference as a foundation for scalable RL in robotic control.
Ego-Motion Aware Target Prediction Module for Robust Multi-Object Tracking
Apr 03, 2024



Multi-object tracking (MOT) is a prominent task in computer vision with application in autonomous driving, responsible for the simultaneous tracking of multiple object trajectories. Detection-based multi-object tracking (DBT) algorithms detect objects using an independent object detector and predict the imminent location of each target. Conventional prediction methods in DBT utilize Kalman Filter(KF) to extrapolate the target location in the upcoming frames by supposing a constant velocity motion model. These methods are especially hindered in autonomous driving applications due to dramatic camera motion or unavailable detections. Such limitations lead to tracking failures manifested by numerous identity switches and disrupted trajectories. In this paper, we introduce a novel KF-based prediction module called the Ego-motion Aware Target Prediction (EMAP) module by focusing on the integration of camera motion and depth information with object motion models. Our proposed method decouples the impact of camera rotational and translational velocity from the object trajectories by reformulating the Kalman Filter. This reformulation enables us to reject the disturbances caused by camera motion and maximizes the reliability of the object motion model. We integrate our module with four state-of-the-art base MOT algorithms, namely OC-SORT, Deep OC-SORT, ByteTrack, and BoT-SORT. In particular, our evaluation on the KITTI MOT dataset demonstrates that EMAP remarkably drops the number of identity switches (IDSW) of OC-SORT and Deep OC-SORT by 73% and 21%, respectively. At the same time, it elevates other performance metrics such as HOTA by more than 5%. Our source code is available at https://github.com/noyzzz/EMAP.
Human-Robot Skill Transfer with Enhanced Compliance via Dynamic Movement Primitives
Apr 12, 2023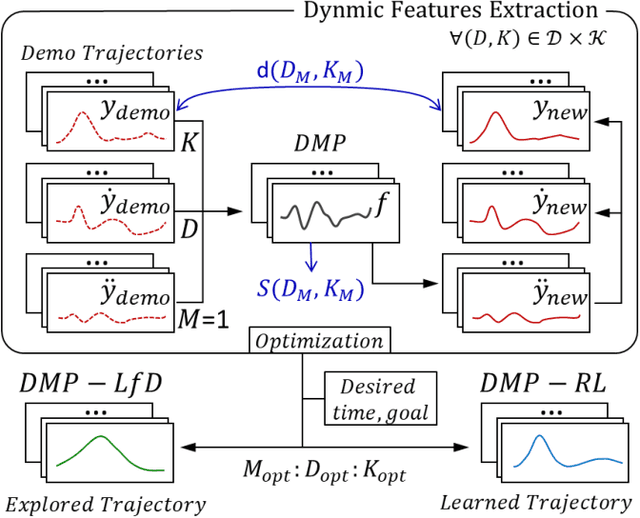
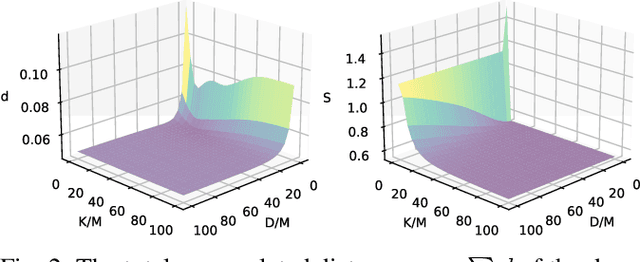
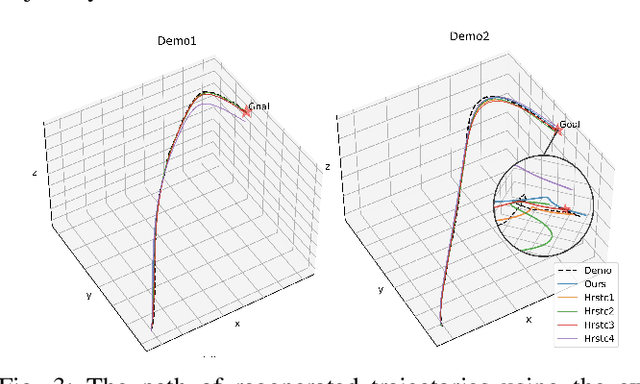
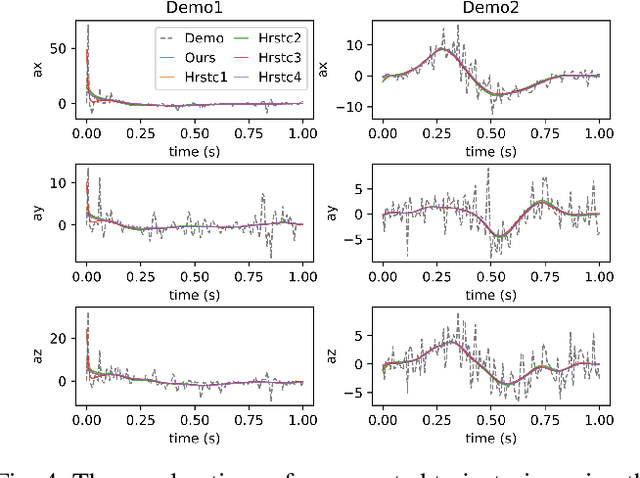
Finding an efficient way to adapt robot trajectory is a priority to improve overall performance of robots. One approach for trajectory planning is through transferring human-like skills to robots by Learning from Demonstrations (LfD). The human demonstration is considered the target motion to mimic. However, human motion is typically optimal for human embodiment but not for robots because of the differences between human biomechanics and robot dynamics. The Dynamic Movement Primitives (DMP) framework is a viable solution for this limitation of LfD, but it requires tuning the second-order dynamics in the formulation. Our contribution is introducing a systematic method to extract the dynamic features from human demonstration to auto-tune the parameters in the DMP framework. In addition to its use with LfD, another utility of the proposed method is that it can readily be used in conjunction with Reinforcement Learning (RL) for robot training. In this way, the extracted features facilitate the transfer of human skills by allowing the robot to explore the possible trajectories more efficiently and increasing robot compliance significantly. We introduced a methodology to extract the dynamic features from multiple trajectories based on the optimization of human-likeness and similarity in the parametric space. Our method was implemented into an actual human-robot setup to extract human dynamic features and used to regenerate the robot trajectories following both LfD and RL with DMP. It resulted in a stable performance of the robot, maintaining a high degree of human-likeness based on accumulated distance error as good as the best heuristic tuning.
Exploiting Symmetry and Heuristic Demonstrations in Off-policy Reinforcement Learning for Robotic Manipulation
Apr 12, 2023



Reinforcement learning demonstrates significant potential in automatically building control policies in numerous domains, but shows low efficiency when applied to robot manipulation tasks due to the curse of dimensionality. To facilitate the learning of such tasks, prior knowledge or heuristics that incorporate inherent simplification can effectively improve the learning performance. This paper aims to define and incorporate the natural symmetry present in physical robotic environments. Then, sample-efficient policies are trained by exploiting the expert demonstrations in symmetrical environments through an amalgamation of reinforcement and behavior cloning, which gives the off-policy learning process a diverse yet compact initiation. Furthermore, it presents a rigorous framework for a recent concept and explores its scope for robot manipulation tasks. The proposed method is validated via two point-to-point reaching tasks of an industrial arm, with and without an obstacle, in a simulation experiment study. A PID controller, which tracks the linear joint-space trajectories with hard-coded temporal logic to produce interim midpoints, is used to generate demonstrations in the study. The results of the study present the effect of the number of demonstrations and quantify the magnitude of behavior cloning to exemplify the possible improvement of model-free reinforcement learning in common manipulation tasks. A comparison study between the proposed method and a traditional off-policy reinforcement learning algorithm indicates its advantage in learning performance and potential value for applications.
Exploiting Intrinsic Stochasticity of Real-Time Simulation to Facilitate Robust Reinforcement Learning for Robot Manipulation
Apr 12, 2023



Simulation is essential to reinforcement learning (RL) before implementation in the real world, especially for safety-critical applications like robot manipulation. Conventionally, RL agents are sensitive to the discrepancies between the simulation and the real world, known as the sim-to-real gap. The application of domain randomization, a technique used to fill this gap, is limited to the imposition of heuristic-randomized models. We investigate the properties of intrinsic stochasticity of real-time simulation (RT-IS) of off-the-shelf simulation software and its potential to improve the robustness of RL methods and the performance of domain randomization. Firstly, we conduct analytical studies to measure the correlation of RT-IS with the occupation of the computer hardware and validate its comparability with the natural stochasticity of a physical robot. Then, we apply the RT-IS feature in the training of an RL agent. The simulation and physical experiment results verify the feasibility and applicability of RT-IS to robust RL agent design for robot manipulation tasks. The RT-IS-powered robust RL agent outperforms conventional RL agents on robots with modeling uncertainties. It requires fewer heuristic randomization and achieves better generalizability than the conventional domain-randomization-powered agents. Our findings provide a new perspective on the sim-to-real problem in practical applications like robot manipulation tasks.