 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTightening the Approximation Error of Adversarial Risk with Auto Loss Function Search
Paper and Code
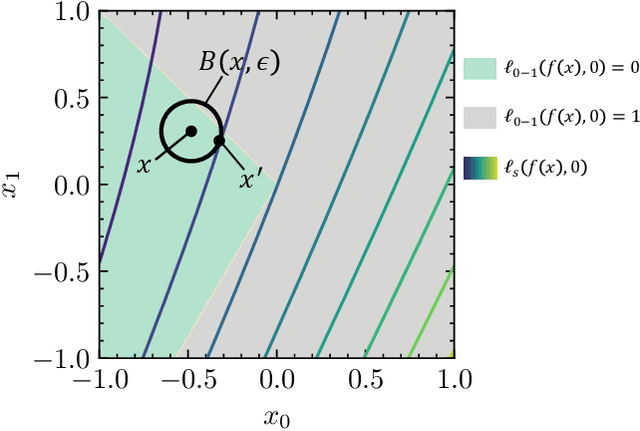

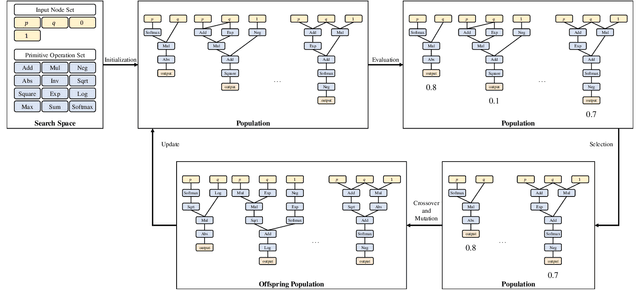
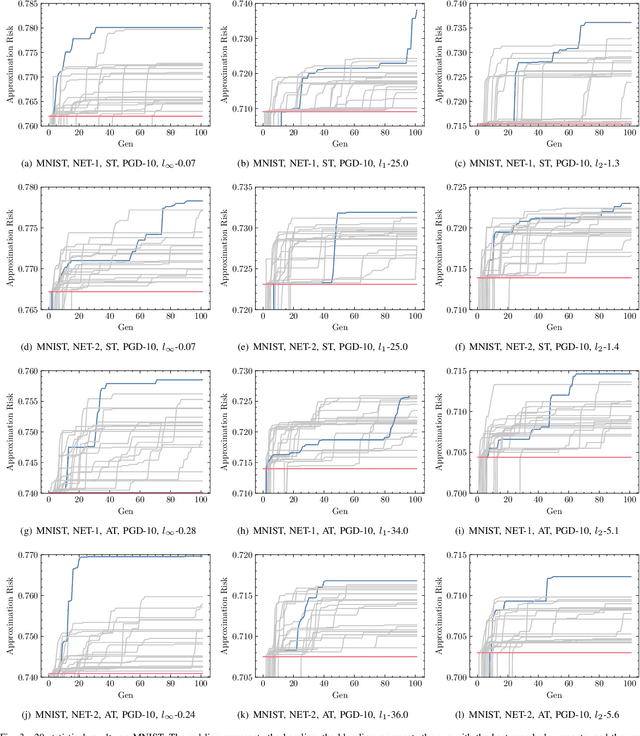
Numerous studies have demonstrated that deep neural networks are easily misled by adversarial examples. Effectively evaluating the adversarial robustness of a model is important for its deployment in practical applications. Currently, a common type of evaluation is to approximate the adversarial risk of a model as a robustness indicator by constructing malicious instances and executing attacks. Unfortunately, there is an error (gap) between the approximate value and the true value. Previous studies manually design attack methods to achieve a smaller error, which is inefficient and may miss a better solution. In this paper, we establish the tightening of the approximation error as an optimization problem and try to solve it with an algorithm. More specifically, we first analyze that replacing the non-convex and discontinuous 0-1 loss with a surrogate loss, a necessary compromise in calculating the approximation, is one of the main reasons for the error. Then we propose AutoLoss-AR, the first method for searching loss functions for tightening the approximation error of adversarial risk. Extensive experiments are conducted in multiple settings. The results demonstrate the effectiveness of the proposed method: the best-discovered loss functions outperform the handcrafted baseline by 0.9%-2.9% and 0.7%-2.0% on MNIST and CIFAR-10, respectively. Besides, we also verify that the searched losses can be transferred to other settings and explore why they are better than the baseline by visualizing the local loss landscape.