 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerson image generation with semantic attention network for person re-identification
Aug 18, 2020
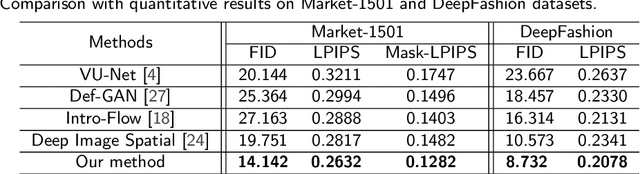
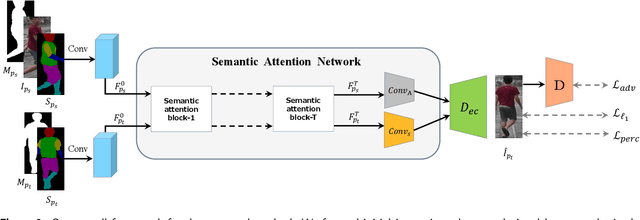
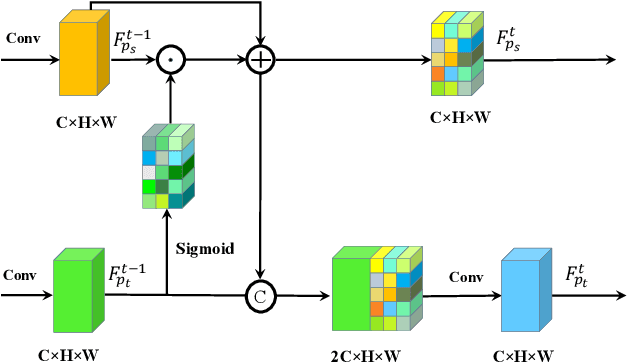
Pose variation is one of the key factors which prevents the network from learning a robust person re-identification (Re-ID) model. To address this issue, we propose a novel person pose-guided image generation method, which is called the semantic attention network. The network consists of several semantic attention blocks, where each block attends to preserve and update the pose code and the clothing textures. The introduction of the binary segmentation mask and the semantic parsing is important for seamlessly stitching foreground and background in the pose-guided image generation. Compared with other methods, our network can characterize better body shape and keep clothing attributes, simultaneously. Our synthesized image can obtain better appearance and shape consistency related to the original image. Experimental results show that our approach is competitive with respect to both quantitative and qualitative results on Market-1501 and DeepFashion. Furthermore, we conduct extensive evaluations by using person re-identification (Re-ID) systems trained with the pose-transferred person based augmented data. The experiment shows that our approach can significantly enhance the person Re-ID accuracy.