 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexiCup: Wireless Multimodal Suction Cup with Dual-Zone Vision-Tactile Sensing
Nov 18, 2025
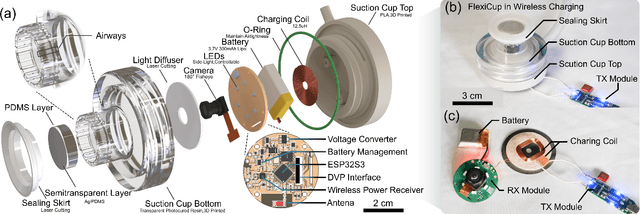
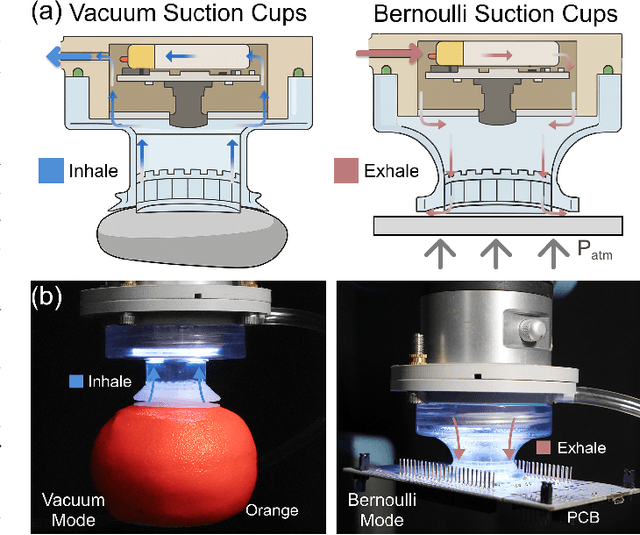
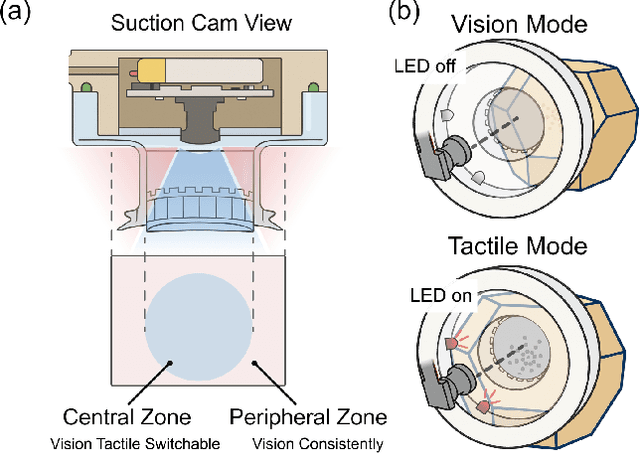
Conventional suction cups lack sensing capabilities for contact-aware manipulation in unstructured environments. This paper presents FlexiCup, a fully wireless multimodal suction cup that integrates dual-zone vision-tactile sensing. The central zone dynamically switches between vision and tactile modalities via illumination control for contact detection, while the peripheral zone provides continuous spatial awareness for approach planning. FlexiCup supports both vacuum and Bernoulli suction modes through modular mechanical configurations, achieving complete wireless autonomy with onboard computation and power. We validate hardware versatility through dual control paradigms. Modular perception-driven grasping across structured surfaces with varying obstacle densities demonstrates comparable performance between vacuum (90.0% mean success) and Bernoulli (86.7% mean success) modes. Diffusion-based end-to-end learning achieves 73.3% success on inclined transport and 66.7% on orange extraction tasks. Ablation studies confirm that multi-head attention coordinating dual-zone observations provides 13% improvements for contact-aware manipulation. Hardware designs and firmware are available at https://anonymous.4open.science/api/repo/FlexiCup-DA7D/file/index.html?v=8f531b44.
MoiréTac: A Dual-Mode Visuotactile Sensor for Multidimensional Perception Using Moiré Pattern Amplification
Sep 16, 2025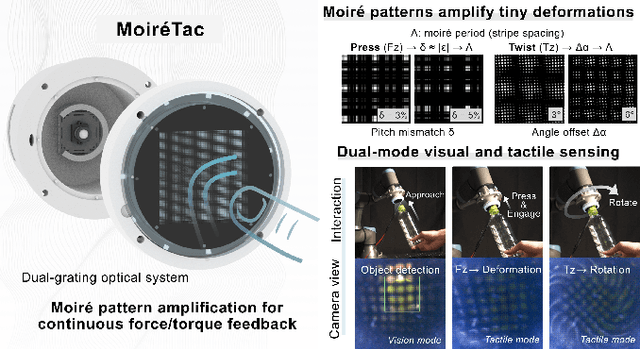

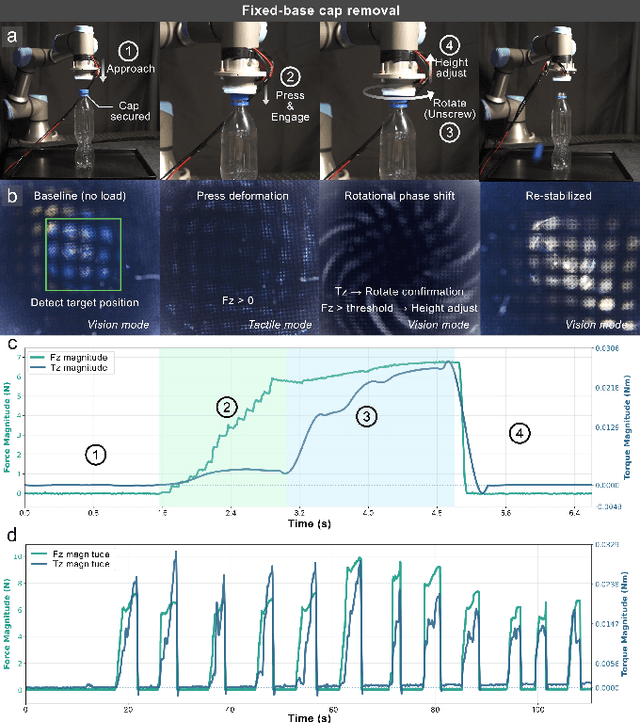

Visuotactile sensors typically employ sparse marker arrays that limit spatial resolution and lack clear analytical force-to-image relationships. To solve this problem, we present \textbf{Moir\'eTac}, a dual-mode sensor that generates dense interference patterns via overlapping micro-gratings within a transparent architecture. When two gratings overlap with misalignment, they create moir\'e patterns that amplify microscopic deformations. The design preserves optical clarity for vision tasks while producing continuous moir\'e fields for tactile sensing, enabling simultaneous 6-axis force/torque measurement, contact localization, and visual perception. We combine physics-based features (brightness, phase gradient, orientation, and period) from moir\'e patterns with deep spatial features. These are mapped to 6-axis force/torque measurements, enabling interpretable regression through end-to-end learning. Experimental results demonstrate three capabilities: force/torque measurement with R^2 > 0.98 across tested axes; sensitivity tuning through geometric parameters (threefold gain adjustment); and vision functionality for object classification despite moir\'e overlay. Finally, we integrate the sensor into a robotic arm for cap removal with coordinated force and torque control, validating its potential for dexterous manipulation.
UltraTac: Integrated Ultrasound-Augmented Visuotactile Sensor for Enhanced Robotic Perception
Aug 29, 2025



Visuotactile sensors provide high-resolution tactile information but are incapable of perceiving the material features of objects. We present UltraTac, an integrated sensor that combines visuotactile imaging with ultrasound sensing through a coaxial optoacoustic architecture. The design shares structural components and achieves consistent sensing regions for both modalities. Additionally, we incorporate acoustic matching into the traditional visuotactile sensor structure, enabling integration of the ultrasound sensing modality without compromising visuotactile performance. Through tactile feedback, we dynamically adjust the operating state of the ultrasound module to achieve flexible functional coordination. Systematic experiments demonstrate three key capabilities: proximity sensing in the 3-8 cm range ($R^2=0.90$), material classification (average accuracy: 99.20%), and texture-material dual-mode object recognition achieving 92.11% accuracy on a 15-class task. Finally, we integrate the sensor into a robotic manipulation system to concurrently detect container surface patterns and internal content, which verifies its potential for advanced human-machine interaction and precise robotic manipulation.
VET: A Visual-Electronic Tactile System for Immersive Human-Machine Interaction
Apr 01, 2025In the pursuit of deeper immersion in human-machine interaction, achieving higher-dimensional tactile input and output on a single interface has become a key research focus. This study introduces the Visual-Electronic Tactile (VET) System, which builds upon vision-based tactile sensors (VBTS) and integrates electrical stimulation feedback to enable bidirectional tactile communication. We propose and implement a system framework that seamlessly integrates an electrical stimulation film with VBTS using a screen-printing preparation process, eliminating interference from traditional methods. While VBTS captures multi-dimensional input through visuotactile signals, electrical stimulation feedback directly stimulates neural pathways, preventing interference with visuotactile information. The potential of the VET system is demonstrated through experiments on finger electrical stimulation sensitivity zones, as well as applications in interactive gaming and robotic arm teleoperation. This system paves the way for new advancements in bidirectional tactile interaction and its broader applications.
AVR: Active Vision-Driven Robotic Precision Manipulation with Viewpoint and Focal Length Optimization
Mar 03, 2025Robotic manipulation within dynamic environments presents challenges to precise control and adaptability. Traditional fixed-view camera systems face challenges adapting to change viewpoints and scale variations, limiting perception and manipulation precision. To tackle these issues, we propose the Active Vision-driven Robotic (AVR) framework, a teleoperation hardware solution that supports dynamic viewpoint and dynamic focal length adjustments to continuously center targets and maintain optimal scale, accompanied by a corresponding algorithm that effectively enhances the success rates of various operational tasks. Using the RoboTwin platform with a real-time image processing plugin, AVR framework improves task success rates by 5%-16% on five manipulation tasks. Physical deployment on a dual-arm system demonstrates in collaborative tasks and 36% precision in screwdriver insertion, outperforming baselines by over 25%. Experimental results confirm that AVR framework enhances environmental perception, manipulation repeatability (40% $\le $1 cm error), and robustness in complex scenarios, paving the way for future robotic precision manipulation methods in the pursuit of human-level robot dexterity and precision.
Exo-ViHa: A Cross-Platform Exoskeleton System with Visual and Haptic Feedback for Efficient Dexterous Skill Learning
Mar 03, 2025Imitation learning has emerged as a powerful paradigm for robot skills learning. However, traditional data collection systems for dexterous manipulation face challenges, including a lack of balance between acquisition efficiency, consistency, and accuracy. To address these issues, we introduce Exo-ViHa, an innovative 3D-printed exoskeleton system that enables users to collect data from a first-person perspective while providing real-time haptic feedback. This system combines a 3D-printed modular structure with a slam camera, a motion capture glove, and a wrist-mounted camera. Various dexterous hands can be installed at the end, enabling it to simultaneously collect the posture of the end effector, hand movements, and visual data. By leveraging the first-person perspective and direct interaction, the exoskeleton enhances the task realism and haptic feedback, improving the consistency between demonstrations and actual robot deployments. In addition, it has cross-platform compatibility with various robotic arms and dexterous hands. Experiments show that the system can significantly improve the success rate and efficiency of data collection for dexterous manipulation tasks.
MoDex: Planning High-Dimensional Dexterous Control via Learning Neural Hand Models
Sep 17, 2024Controlling hands in the high-dimensional action space has been a longstanding challenge, yet humans naturally perform dexterous tasks with ease. In this paper, we draw inspiration from the human embodied cognition and reconsider dexterous hands as learnable systems. Specifically, we introduce MoDex, a framework which employs a neural hand model to capture the dynamical characteristics of hand movements. Based on the model, a bidirectional planning method is developed, which demonstrates efficiency in both training and inference. The method is further integrated with a large language model to generate various gestures such as ``Scissorshand" and ``Rock\&Roll." Moreover, we show that decomposing the system dynamics into a pretrained hand model and an external model improves data efficiency, as supported by both theoretical analysis and empirical experiments. Additional visualization results are available at https://tongwu19.github.io/MoDex.