 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-aware Fine-tuning for Code Pre-trained Models
Paper and Code
Apr 11, 2024
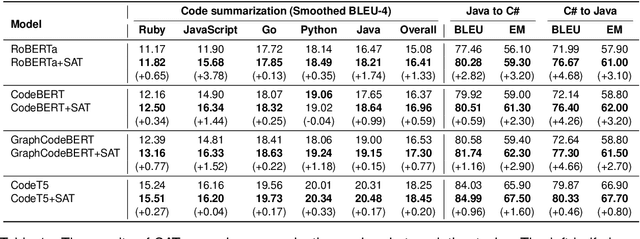

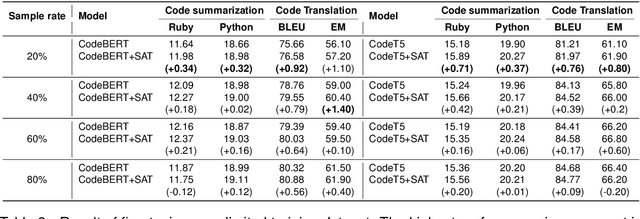
Over the past few years, we have witnessed remarkable advancements in Code Pre-trained Models (CodePTMs). These models achieved excellent representation capabilities by designing structure-based pre-training tasks for code. However, how to enhance the absorption of structural knowledge when fine-tuning CodePTMs still remains a significant challenge. To fill this gap, in this paper, we present Structure-aware Fine-tuning (SAT), a novel structure-enhanced and plug-and-play fine-tuning method for CodePTMs. We first propose a structure loss to quantify the difference between the information learned by CodePTMs and the knowledge extracted from code structure. Specifically, we use the attention scores extracted from Transformer layer as the learned structural information, and the shortest path length between leaves in abstract syntax trees as the structural knowledge. Subsequently, multi-task learning is introduced to improve the performance of fine-tuning. Experiments conducted on four pre-trained models and two generation tasks demonstrate the effectiveness of our proposed method as a plug-and-play solution. Furthermore, we observed that SAT can benefit CodePTMs more with limited training data.