 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of Item Difficulty for Reading Comprehension Items by Creation of Annotated Item Repository
Feb 28, 2025Prediction of item difficulty based on its text content is of substantial interest. In this paper, we focus on the related problem of recovering IRT-based difficulty when the data originally reported item p-value (percent correct responses). We model this item difficulty using a repository of reading passages and student data from US standardized tests from New York and Texas for grades 3-8 spanning the years 2017-23. This repository is annotated with meta-data on (1) linguistic features of the reading items, (2) test features of the passage, and (3) context features. A penalized regression prediction model with all these features can predict item difficulty with RMSE 0.52 compared to baseline RMSE of 0.92, and with a correlation of 0.77 between true and predicted difficulty. We supplement these features with embeddings from LLMs (ModernBERT, BERT, and LlAMA), which marginally improve item difficulty prediction. When models use only item linguistic features or LLM embeddings, prediction performance is similar, which suggests that only one of these feature categories may be required. This item difficulty prediction model can be used to filter and categorize reading items and will be made publicly available for use by other stakeholders.
Psychometric Alignment: Capturing Human Knowledge Distributions via Language Models
Jul 22, 2024



Language models (LMs) are increasingly used to simulate human-like responses in scenarios where accurately mimicking a population's behavior can guide decision-making, such as in developing educational materials and designing public policies. The objective of these simulations is for LMs to capture the variations in human responses, rather than merely providing the expected correct answers. Prior work has shown that LMs often generate unrealistically accurate responses, but there are no established metrics to quantify how closely the knowledge distribution of LMs aligns with that of humans. To address this, we introduce "psychometric alignment," a metric that measures the extent to which LMs reflect human knowledge distribution. Assessing this alignment involves collecting responses from both LMs and humans to the same set of test items and using Item Response Theory to analyze the differences in item functioning between the groups. We demonstrate that our metric can capture important variations in populations that traditional metrics, like differences in accuracy, fail to capture. We apply this metric to assess existing LMs for their alignment with human knowledge distributions across three real-world domains. We find significant misalignment between LMs and human populations, though using persona-based prompts can improve alignment. Interestingly, smaller LMs tend to achieve greater psychometric alignment than larger LMs. Further, training LMs on human response data from the target distribution enhances their psychometric alignment on unseen test items, but the effectiveness of such training varies across domains.
Modeling Item Response Theory with Stochastic Variational Inference
Aug 26, 2021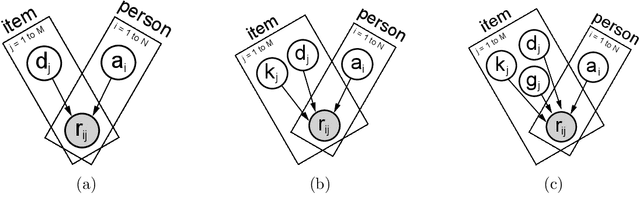
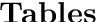
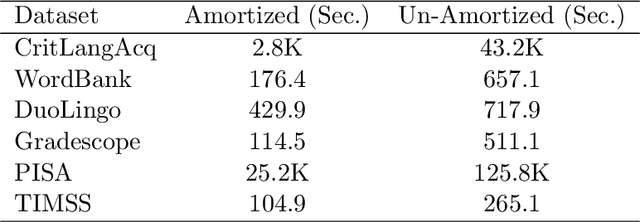
Item Response Theory (IRT) is a ubiquitous model for understanding human behaviors and attitudes based on their responses to questions. Large modern datasets offer opportunities to capture more nuances in human behavior, potentially improving psychometric modeling leading to improved scientific understanding and public policy. However, while larger datasets allow for more flexible approaches, many contemporary algorithms for fitting IRT models may also have massive computational demands that forbid real-world application. To address this bottleneck, we introduce a variational Bayesian inference algorithm for IRT, and show that it is fast and scalable without sacrificing accuracy. Applying this method to five large-scale item response datasets from cognitive science and education yields higher log likelihoods and higher accuracy in imputing missing data than alternative inference algorithms. Using this new inference approach we then generalize IRT with expressive Bayesian models of responses, leveraging recent advances in deep learning to capture nonlinear item characteristic curves (ICC) with neural networks. Using an eigth-grade mathematics test from TIMSS, we show our nonlinear IRT models can capture interesting asymmetric ICCs. The algorithm implementation is open-source, and easily usable.
Variational Item Response Theory: Fast, Accurate, and Expressive
Feb 01, 2020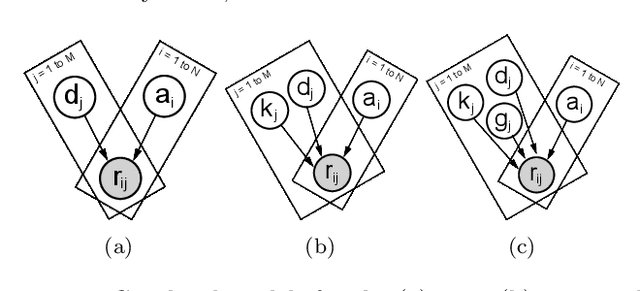


Item Response Theory is a ubiquitous algorithm used around the world to understand humans based on their responses to questions in fields as diverse as education, medicine and psychology. However, for medium to large datasets, contemporary solutions pose a tradeoff: either have bayesian, interpretable, accurate estimates or have fast computation. We introduce variational inference and deep generative models to Item Response Theory to offer the best of both worlds. The resulting algorithm is (a) orders of magnitude faster when inferring on the classical model, (b) naturally extends to more complicated input than binary correct/incorrect, and more expressive deep bayesian models of responses. Applying this method to five large-scale item response datasets from cognitive science and education, we find improvements in imputing missing data and better log likelihoods. The open-source algorithm is immediately usable.
AI and Holistic Review: Informing Human Reading in College Admissions
Dec 17, 2019


College admissions in the United States is carried out by a human-centered method of evaluation known as holistic review, which typically involves reading original narrative essays submitted by each applicant. The legitimacy and fairness of holistic review, which gives human readers significant discretion over determining each applicant's fitness for admission, has been repeatedly challenged in courtrooms and the public sphere. Using a unique corpus of 283,676 application essays submitted to a large, selective, state university system between 2015 and 2016, we assess the extent to which applicant demographic characteristics can be inferred from application essays. We find a relatively interpretable classifier (logistic regression) was able to predict gender and household income with high levels of accuracy. Findings suggest that data auditing might be useful in informing holistic review, and perhaps other evaluative systems, by checking potential bias in human or computational readings.
Curve Fitting from Probabilistic Emissions and Applications to Dynamic Item Response Theory
Sep 09, 2019


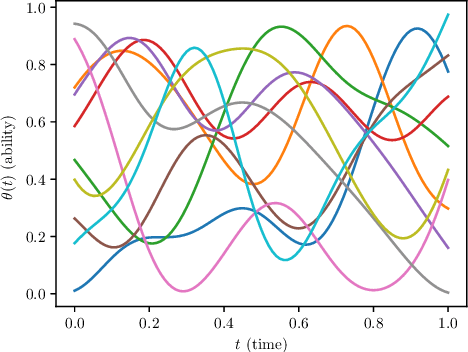
Item response theory (IRT) models are widely used in psychometrics and educational measurement, being deployed in many high stakes tests such as the GRE aptitude test. IRT has largely focused on estimation of a single latent trait (e.g. ability) that remains static through the collection of item responses. However, in contemporary settings where item responses are being continuously collected, such as Massive Open Online Courses (MOOCs), interest will naturally be on the dynamics of ability, thus complicating usage of traditional IRT models. We propose DynAEsti, an augmentation of the traditional IRT Expectation Maximization algorithm that allows ability to be a continuously varying curve over time. In the process, we develop CurvFiFE, a novel non-parametric continuous-time technique that handles the curve-fitting/regression problem extended to address more general probabilistic emissions (as opposed to simply noisy data points). Furthermore, to accomplish this, we develop a novel technique called grafting, which can successfully approximate distributions represented by graphical models when other popular techniques like Loopy Belief Propogation (LBP) and Variational Inference (VI) fail. The performance of DynAEsti is evaluated through simulation, where we achieve results comparable to the optimal of what is observed in the static ability scenario. Finally, DynAEsti is applied to a longitudinal performance dataset (80-years of competitive golf at the 18-hole Masters Tournament) to demonstrate its ability to recover key properties of human performance and the heterogeneous characteristics of the different holes. Python code for CurvFiFE and DynAEsti is publicly available at github.com/chausies/DynAEstiAndCurvFiFE. This is the full version of our ICDM 2019 paper.