 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Item Response Theory with Stochastic Variational Inference
Aug 26, 2021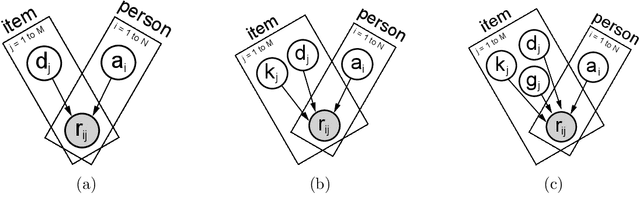
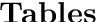
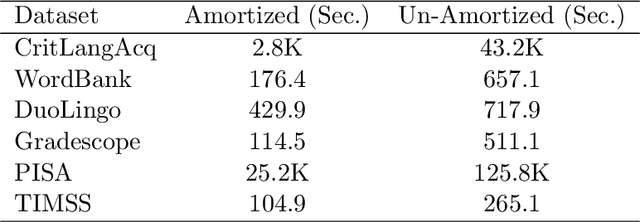
Item Response Theory (IRT) is a ubiquitous model for understanding human behaviors and attitudes based on their responses to questions. Large modern datasets offer opportunities to capture more nuances in human behavior, potentially improving psychometric modeling leading to improved scientific understanding and public policy. However, while larger datasets allow for more flexible approaches, many contemporary algorithms for fitting IRT models may also have massive computational demands that forbid real-world application. To address this bottleneck, we introduce a variational Bayesian inference algorithm for IRT, and show that it is fast and scalable without sacrificing accuracy. Applying this method to five large-scale item response datasets from cognitive science and education yields higher log likelihoods and higher accuracy in imputing missing data than alternative inference algorithms. Using this new inference approach we then generalize IRT with expressive Bayesian models of responses, leveraging recent advances in deep learning to capture nonlinear item characteristic curves (ICC) with neural networks. Using an eigth-grade mathematics test from TIMSS, we show our nonlinear IRT models can capture interesting asymmetric ICCs. The algorithm implementation is open-source, and easily usable.
Variational Item Response Theory: Fast, Accurate, and Expressive
Feb 01, 2020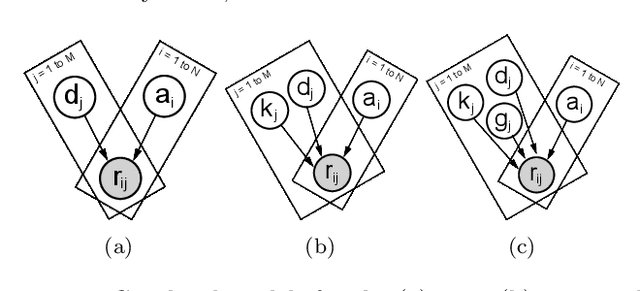


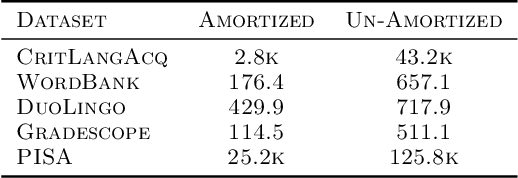
Item Response Theory is a ubiquitous algorithm used around the world to understand humans based on their responses to questions in fields as diverse as education, medicine and psychology. However, for medium to large datasets, contemporary solutions pose a tradeoff: either have bayesian, interpretable, accurate estimates or have fast computation. We introduce variational inference and deep generative models to Item Response Theory to offer the best of both worlds. The resulting algorithm is (a) orders of magnitude faster when inferring on the classical model, (b) naturally extends to more complicated input than binary correct/incorrect, and more expressive deep bayesian models of responses. Applying this method to five large-scale item response datasets from cognitive science and education, we find improvements in imputing missing data and better log likelihoods. The open-source algorithm is immediately usable.