 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Long Policy Evaluation with Novel Actions
Jul 04, 2024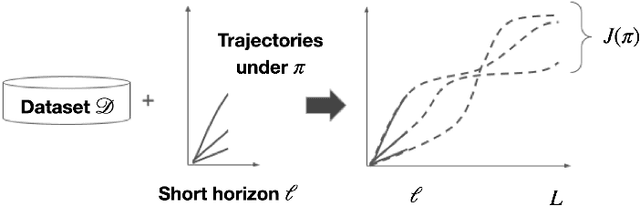

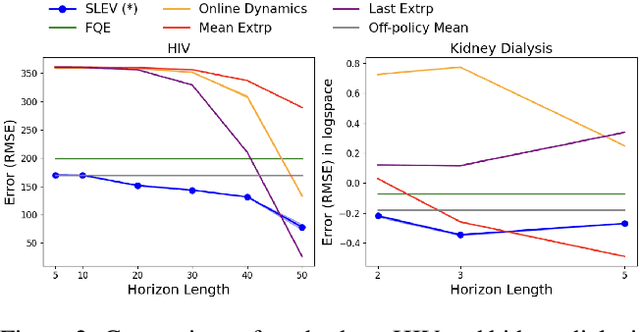

From incorporating LLMs in education, to identifying new drugs and improving ways to charge batteries, innovators constantly try new strategies in search of better long-term outcomes for students, patients and consumers. One major bottleneck in this innovation cycle is the amount of time it takes to observe the downstream effects of a decision policy that incorporates new interventions. The key question is whether we can quickly evaluate long-term outcomes of a new decision policy without making long-term observations. Organizations often have access to prior data about past decision policies and their outcomes, evaluated over the full horizon of interest. Motivated by this, we introduce a new setting for short-long policy evaluation for sequential decision making tasks. Our proposed methods significantly outperform prior results on simulators of HIV treatment, kidney dialysis and battery charging. We also demonstrate that our methods can be useful for applications in AI safety by quickly identifying when a new decision policy is likely to have substantially lower performance than past policies.
Exploring Optimal Control With Observations at a Cost
Jun 29, 2020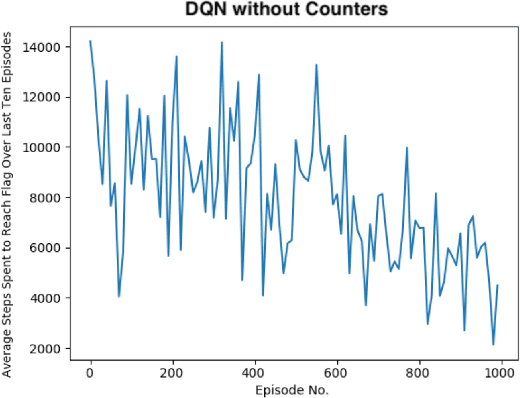
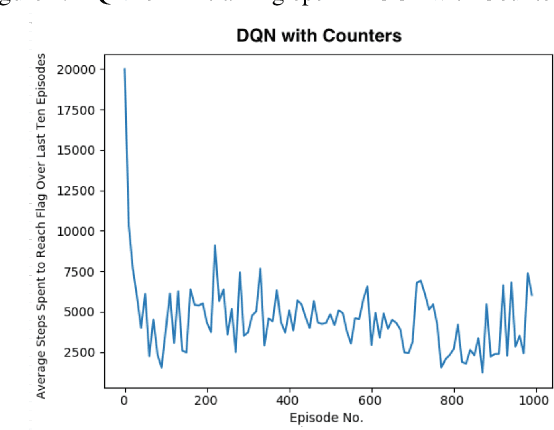
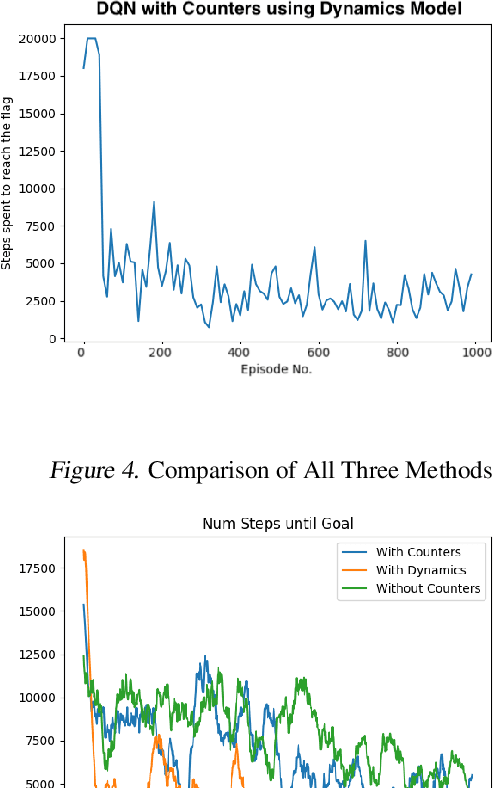
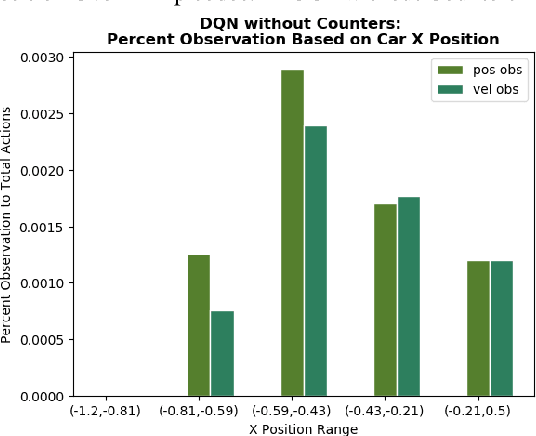
There has been a current trend in reinforcement learning for healthcare literature, where in order to prepare clinical datasets, researchers will carry forward the last results of the non-administered test known as the last-observation-carried-forward (LOCF) value to fill in gaps, assuming that it is still an accurate indicator of the patient's current state. These values are carried forward without maintaining information about exactly how these values were imputed, leading to ambiguity. Our approach models this problem using OpenAI Gym's Mountain Car and aims to address when to observe the patient's physiological state and partly how to intervene, as we have assumed we can only act after following an observation. So far, we have found that for a last-observation-carried-forward implementation of the state space, augmenting the state with counters for each state variable tracking the time since last observation was made, improves the predictive performance of an agent, supporting the notion of "informative missingness", and using a neural network based Dynamics Model to predict the most probable next state value of non-observed state variables instead of carrying forward the last observed value through LOCF further improves the agent's performance, leading to faster convergence and reduced variance.