 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Achieve More with Less? Exploring Data Augmentation for Toxic Comment Classification
Jul 02, 2020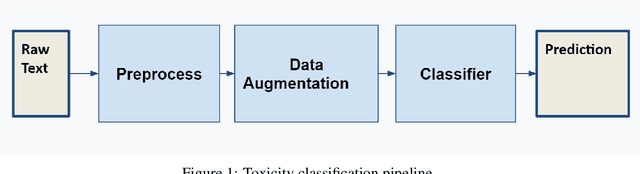
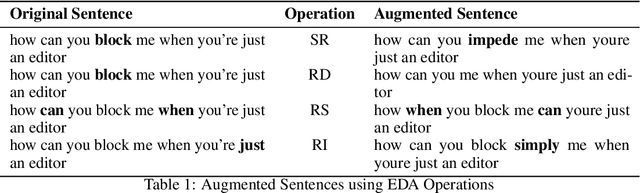
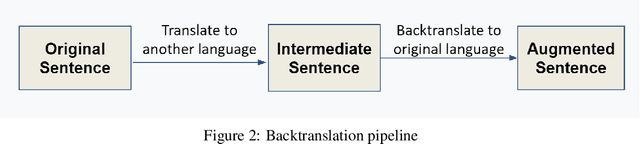

This paper tackles one of the greatest limitations in Machine Learning: Data Scarcity. Specifically, we explore whether high accuracy classifiers can be built from small datasets, utilizing a combination of data augmentation techniques and machine learning algorithms. In this paper, we experiment with Easy Data Augmentation (EDA) and Backtranslation, as well as with three popular learning algorithms, Logistic Regression, Support Vector Machine (SVM), and Bidirectional Long Short-Term Memory Network (Bi-LSTM). For our experimentation, we utilize the Wikipedia Toxic Comments dataset so that in the process of exploring the benefits of data augmentation, we can develop a model to detect and classify toxic speech in comments to help fight back against cyberbullying and online harassment. Ultimately, we found that data augmentation techniques can be used to significantly boost the performance of classifiers and are an excellent strategy to combat lack of data in NLP problems.
Exploring Optimal Control With Observations at a Cost
Jun 29, 2020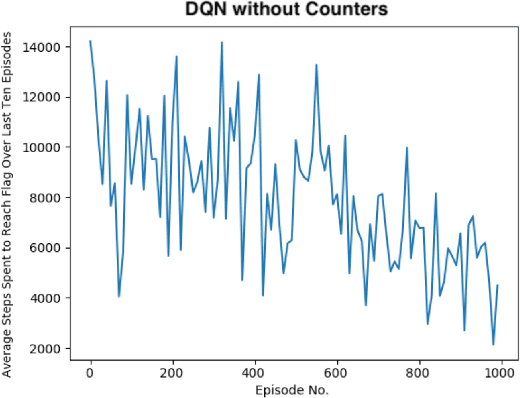
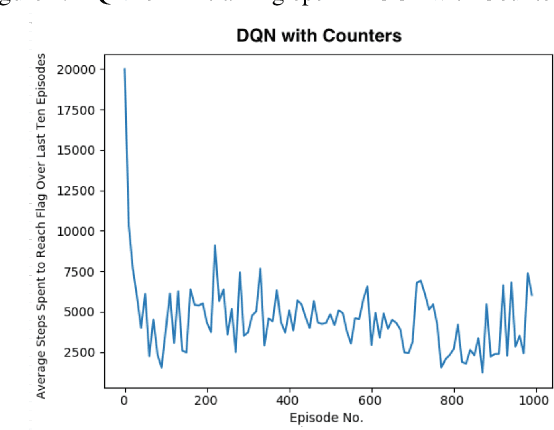
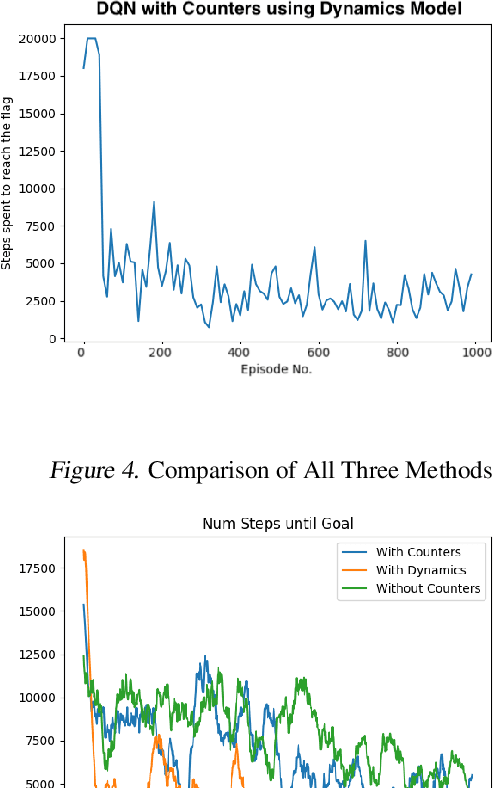
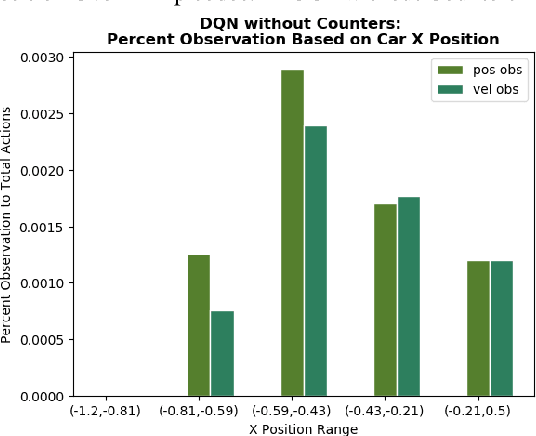
There has been a current trend in reinforcement learning for healthcare literature, where in order to prepare clinical datasets, researchers will carry forward the last results of the non-administered test known as the last-observation-carried-forward (LOCF) value to fill in gaps, assuming that it is still an accurate indicator of the patient's current state. These values are carried forward without maintaining information about exactly how these values were imputed, leading to ambiguity. Our approach models this problem using OpenAI Gym's Mountain Car and aims to address when to observe the patient's physiological state and partly how to intervene, as we have assumed we can only act after following an observation. So far, we have found that for a last-observation-carried-forward implementation of the state space, augmenting the state with counters for each state variable tracking the time since last observation was made, improves the predictive performance of an agent, supporting the notion of "informative missingness", and using a neural network based Dynamics Model to predict the most probable next state value of non-observed state variables instead of carrying forward the last observed value through LOCF further improves the agent's performance, leading to faster convergence and reduced variance.
Keep Your AI-es on the Road: Tackling Distracted Driver Detection with Convolutional Neural Networks and Targeted Data Augmentation
Jun 24, 2020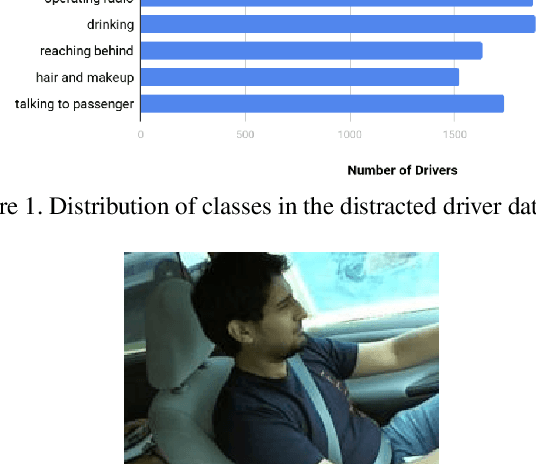

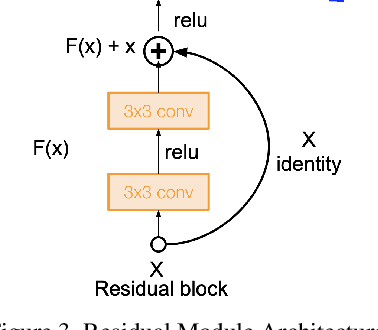

According to the World Health Organization, distracted driving is one of the leading cause of motor accidents and deaths in the world. In our study, we tackle the problem of distracted driving by aiming to build a robust multi-class classifier to detect and identify different forms of driver inattention using the State Farm Distracted Driving Dataset. We utilize combinations of pretrained image classification models, classical data augmentation, OpenCV based image preprocessing and skin segmentation augmentation approaches. Our best performing model combines several augmentation techniques, including skin segmentation, facial blurring, and classical augmentation techniques. This model achieves an approximately 15% increase in F1 score over the baseline, thus showing the promise in these techniques in enhancing the power of neural networks for the task of distracted driver detection.