 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Achieve More with Less? Exploring Data Augmentation for Toxic Comment Classification
Jul 02, 2020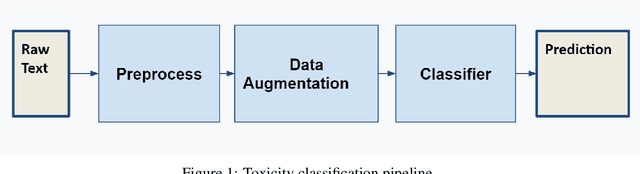
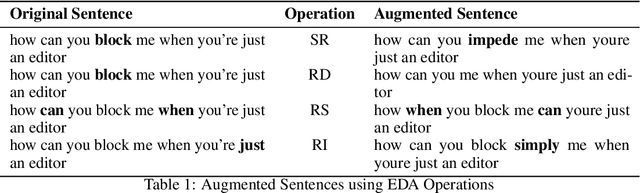
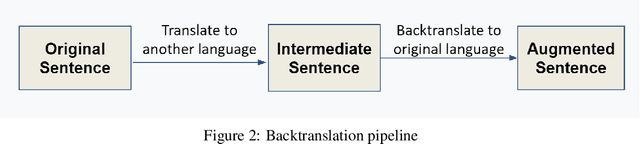

This paper tackles one of the greatest limitations in Machine Learning: Data Scarcity. Specifically, we explore whether high accuracy classifiers can be built from small datasets, utilizing a combination of data augmentation techniques and machine learning algorithms. In this paper, we experiment with Easy Data Augmentation (EDA) and Backtranslation, as well as with three popular learning algorithms, Logistic Regression, Support Vector Machine (SVM), and Bidirectional Long Short-Term Memory Network (Bi-LSTM). For our experimentation, we utilize the Wikipedia Toxic Comments dataset so that in the process of exploring the benefits of data augmentation, we can develop a model to detect and classify toxic speech in comments to help fight back against cyberbullying and online harassment. Ultimately, we found that data augmentation techniques can be used to significantly boost the performance of classifiers and are an excellent strategy to combat lack of data in NLP problems.
Learning a Multi-Modal Policy via Imitating Demonstrations with Mixed Behaviors
Mar 25, 2019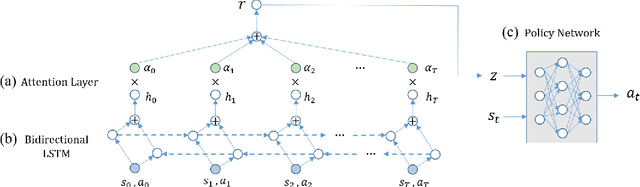
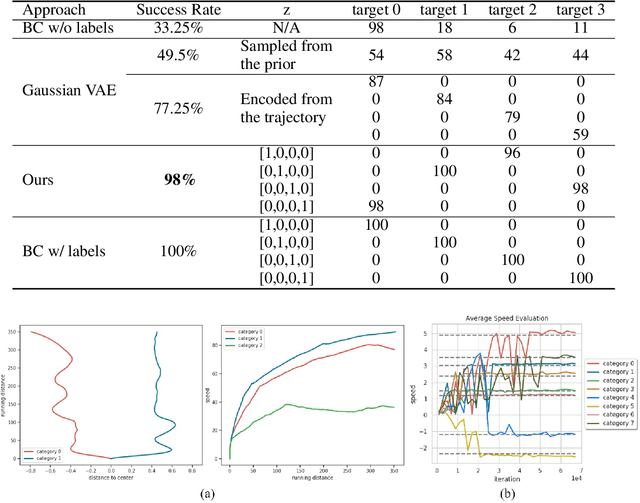


We propose a novel approach to train a multi-modal policy from mixed demonstrations without their behavior labels. We develop a method to discover the latent factors of variation in the demonstrations. Specifically, our method is based on the variational autoencoder with a categorical latent variable. The encoder infers discrete latent factors corresponding to different behaviors from demonstrations. The decoder, as a policy, performs the behaviors accordingly. Once learned, the policy is able to reproduce a specific behavior by simply conditioning on a categorical vector. We evaluate our method on three different tasks, including a challenging task with high-dimensional visual inputs. Experimental results show that our approach is better than various baseline methods and competitive with a multi-modal policy trained by ground truth behavior labels.