 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Multi-Modal Policy via Imitating Demonstrations with Mixed Behaviors
Mar 25, 2019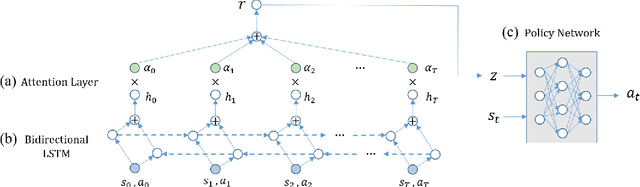
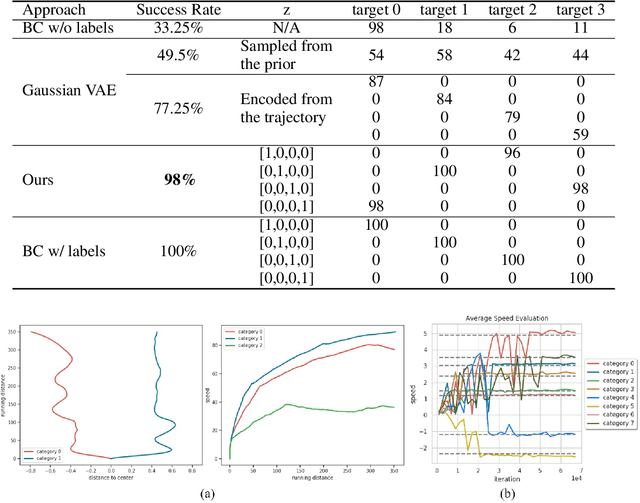


We propose a novel approach to train a multi-modal policy from mixed demonstrations without their behavior labels. We develop a method to discover the latent factors of variation in the demonstrations. Specifically, our method is based on the variational autoencoder with a categorical latent variable. The encoder infers discrete latent factors corresponding to different behaviors from demonstrations. The decoder, as a policy, performs the behaviors accordingly. Once learned, the policy is able to reproduce a specific behavior by simply conditioning on a categorical vector. We evaluate our method on three different tasks, including a challenging task with high-dimensional visual inputs. Experimental results show that our approach is better than various baseline methods and competitive with a multi-modal policy trained by ground truth behavior labels.