 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
Nudging: Inference-time Alignment via Model Collaboration
Oct 15, 2024



Large language models (LLMs) require alignment, such as instruction-tuning or reinforcement learning from human feedback, to effectively and safely follow user instructions. This process necessitates training aligned versions for every model size in each model family, resulting in significant computational overhead. In this work, we propose nudging, a simple, plug-and-play, and training-free algorithm that aligns any base model at inference time using a small aligned model. Nudging is motivated by recent findings that alignment primarily alters the model's behavior on a small subset of stylistic tokens, such as "Sure" or "Thank". We find that base models are significantly more uncertain when generating these tokens. Leveraging this observation, nudging employs a small aligned model to generate nudging tokens to steer the large base model's output toward desired directions when the base model's uncertainty is high. We evaluate the effectiveness of nudging across 3 model families and 13 tasks, covering reasoning, general knowledge, instruction following, and safety benchmarks. Without any additional training, nudging a large base model with a 7x - 14x smaller aligned model achieves zero-shot performance comparable to, and sometimes surpassing, that of large aligned models. For example, nudging OLMo-7b with OLMo-1b-instruct, affecting less than 9% of tokens, achieves a 10% absolute improvement on GSM8K over OLMo-7b-instruct. Unlike prior inference-time tuning methods, nudging enables off-the-shelf collaboration between model families. For instance, nudging Gemma-2-27b with Llama-2-7b-chat outperforms Llama-2-70b-chat on various tasks. Overall, this work introduces a simple yet powerful approach to token-level model collaboration, offering a modular solution to LLM alignment. Our project website: https://fywalter.github.io/nudging/ .
Towards a Mechanistic Interpretation of Multi-Step Reasoning Capabilities of Language Models
Oct 23, 2023
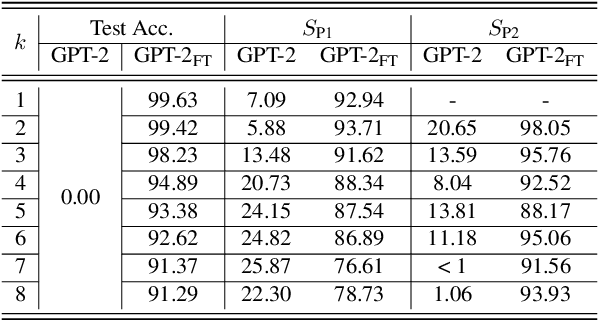

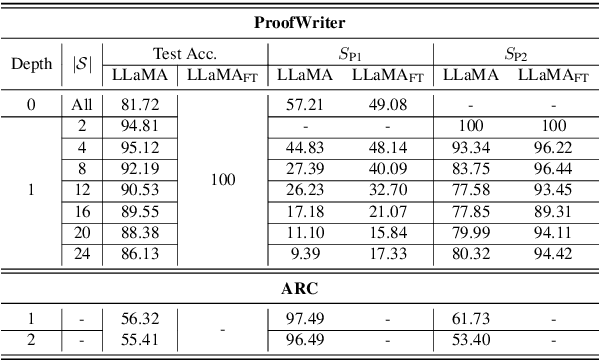
Recent work has shown that language models (LMs) have strong multi-step (i.e., procedural) reasoning capabilities. However, it is unclear whether LMs perform these tasks by cheating with answers memorized from pretraining corpus, or, via a multi-step reasoning mechanism. In this paper, we try to answer this question by exploring a mechanistic interpretation of LMs for multi-step reasoning tasks. Concretely, we hypothesize that the LM implicitly embeds a reasoning tree resembling the correct reasoning process within it. We test this hypothesis by introducing a new probing approach (called MechanisticProbe) that recovers the reasoning tree from the model's attention patterns. We use our probe to analyze two LMs: GPT-2 on a synthetic task (k-th smallest element), and LLaMA on two simple language-based reasoning tasks (ProofWriter & AI2 Reasoning Challenge). We show that MechanisticProbe is able to detect the information of the reasoning tree from the model's attentions for most examples, suggesting that the LM indeed is going through a process of multi-step reasoning within its architecture in many cases.
Mitigating Label Biases for In-context Learning
Jun 10, 2023



Various design settings for in-context learning (ICL), such as the choice and order of the in-context examples, can bias a model toward a particular prediction without being reflective of an understanding of the task. While many studies discuss these design choices, there have been few systematic investigations into categorizing them and mitigating their impact. In this work, we define a typology for three types of label biases in ICL for text classification: vanilla-label bias, context-label bias, and domain-label bias (which we conceptualize and detect for the first time). Our analysis demonstrates that prior label bias calibration methods fall short of addressing all three types of biases. Specifically, domain-label bias restricts LLMs to random-level performance on many tasks regardless of the choice of in-context examples. To mitigate the effect of these biases, we propose a simple bias calibration method that estimates a language model's label bias using random in-domain words from the task corpus. After controlling for this estimated bias when making predictions, our novel domain-context calibration significantly improves the ICL performance of GPT-J and GPT-3 on a wide range of tasks. The gain is substantial on tasks with large domain-label bias (up to 37% in Macro-F1). Furthermore, our results generalize to models with different scales, pretraining methods, and manually-designed task instructions, showing the prevalence of label biases in ICL.
Beyond prompting: Making Pre-trained Language Models Better Zero-shot Learners by Clustering Representations
Oct 29, 2022



Recent work has demonstrated that pre-trained language models (PLMs) are zero-shot learners. However, most existing zero-shot methods involve heavy human engineering or complicated self-training pipelines, hindering their application to new situations. In this work, we show that zero-shot text classification can be improved simply by clustering texts in the embedding spaces of PLMs. Specifically, we fit the unlabeled texts with a Bayesian Gaussian Mixture Model after initializing cluster positions and shapes using class names. Despite its simplicity, this approach achieves superior or comparable performance on both topic and sentiment classification datasets and outperforms prior works significantly on unbalanced datasets. We further explore the applicability of our clustering approach by evaluating it on 14 datasets with more diverse topics, text lengths, and numbers of classes. Our approach achieves an average of 20% absolute improvement over prompt-based zero-shot learning. Finally, we compare different PLM embedding spaces and find that texts are well-clustered by topics even if the PLM is not explicitly pre-trained to generate meaningful sentence embeddings. This work indicates that PLM embeddings can categorize texts without task-specific fine-tuning, thus providing a new way to analyze and utilize their knowledge and zero-shot learning ability.