 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsense Knowledge Mining from Term Definitions
Paper and Code
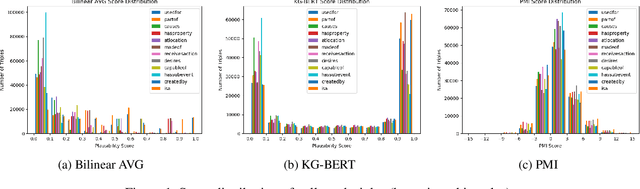
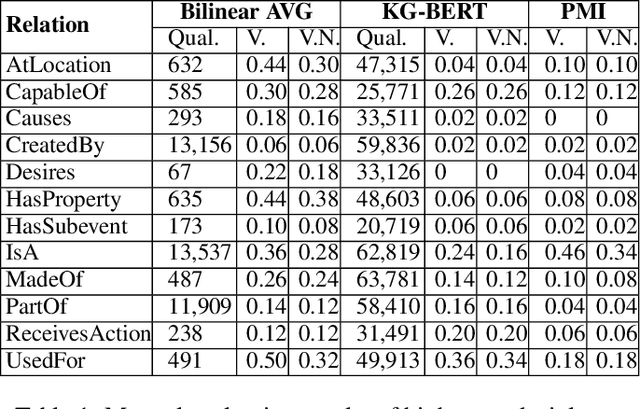
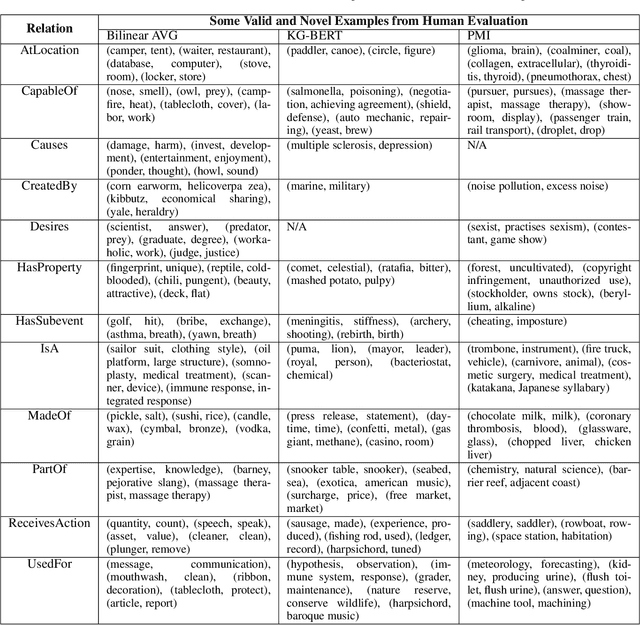

Commonsense knowledge has proven to be beneficial to a variety of application areas, including question answering and natural language understanding. Previous work explored collecting commonsense knowledge triples automatically from text to increase the coverage of current commonsense knowledge graphs. We investigate a few machine learning approaches to mining commonsense knowledge triples using dictionary term definitions as inputs and provide some initial evaluation of the results. We start from extracting candidate triples using part-of-speech tag patterns from text, and then compare the performance of three existing models for triple scoring. Our experiments show that term definitions contain some valid and novel commonsense knowledge triples for some semantic relations, and also indicate some challenges with using existing triple scoring models.