 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Clinical Context for User-Centered Explainability: A Diabetes Use Case
Jul 15, 2021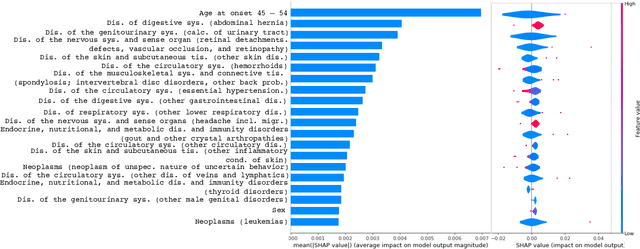

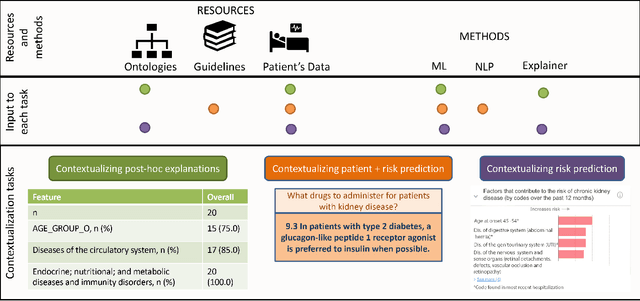
Academic advances of AI models in high-precision domains, like healthcare, need to be made explainable in order to enhance real-world adoption. Our past studies and ongoing interactions indicate that medical experts can use AI systems with greater trust if there are ways to connect the model inferences about patients to explanations that are tied back to the context of use. Specifically, risk prediction is a complex problem of diagnostic and interventional importance to clinicians wherein they consult different sources to make decisions. To enable the adoption of the ever improving AI risk prediction models in practice, we have begun to explore techniques to contextualize such models along three dimensions of interest: the patients' clinical state, AI predictions about their risk of complications, and algorithmic explanations supporting the predictions. We validate the importance of these dimensions by implementing a proof-of-concept (POC) in type-2 diabetes (T2DM) use case where we assess the risk of chronic kidney disease (CKD) - a common T2DM comorbidity. Within the POC, we include risk prediction models for CKD, post-hoc explainers of the predictions, and other natural-language modules which operationalize domain knowledge and CPGs to provide context. With primary care physicians (PCP) as our end-users, we present our initial results and clinician feedback in this paper. Our POC approach covers multiple knowledge sources and clinical scenarios, blends knowledge to explain data and predictions to PCPs, and received an enthusiastic response from our medical expert.
Personalized Food Recommendation as Constrained Question Answering over a Large-scale Food Knowledge Graph
Jan 05, 2021
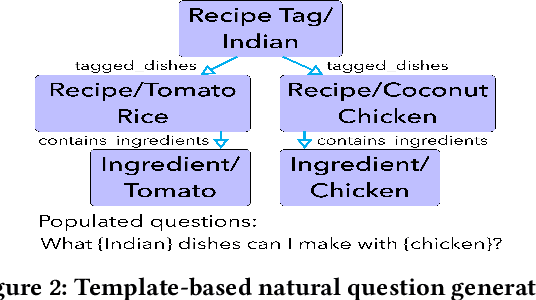

Food recommendation has become an important means to help guide users to adopt healthy dietary habits. Previous works on food recommendation either i) fail to consider users' explicit requirements, ii) ignore crucial health factors (e.g., allergies and nutrition needs), or iii) do not utilize the rich food knowledge for recommending healthy recipes. To address these limitations, we propose a novel problem formulation for food recommendation, modeling this task as constrained question answering over a large-scale food knowledge base/graph (KBQA). Besides the requirements from the user query, personalized requirements from the user's dietary preferences and health guidelines are handled in a unified way as additional constraints to the QA system. To validate this idea, we create a QA style dataset for personalized food recommendation based on a large-scale food knowledge graph and health guidelines. Furthermore, we propose a KBQA-based personalized food recommendation framework which is equipped with novel techniques for handling negations and numerical comparisons in the queries. Experimental results on the benchmark show that our approach significantly outperforms non-personalized counterparts (average 59.7% absolute improvement across various evaluation metrics), and is able to recommend more relevant and healthier recipes.
A Framework for Generating Explanations from Temporal Personal Health Data
Mar 20, 2020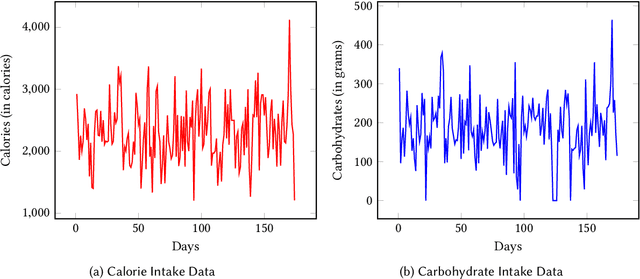
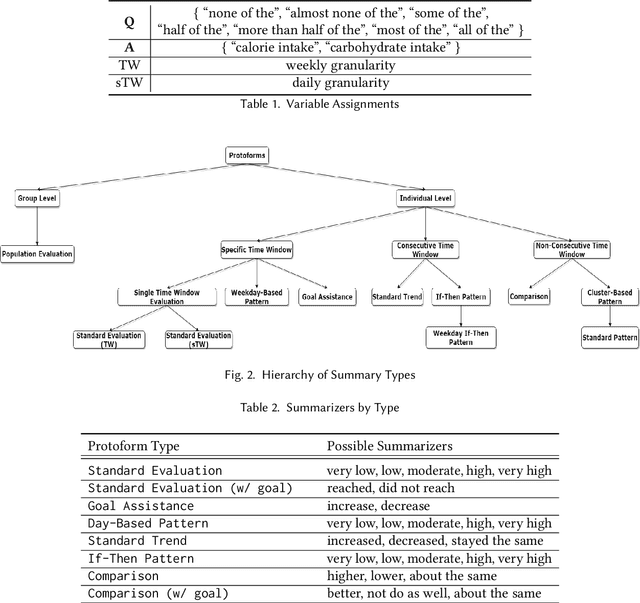
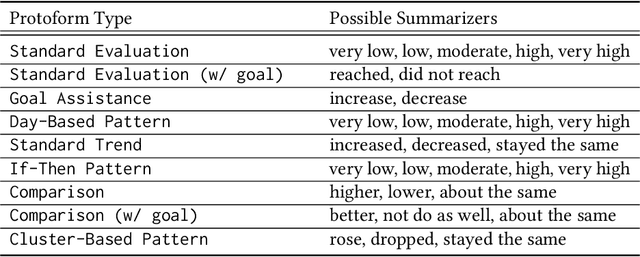
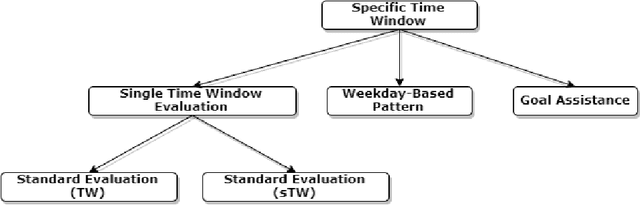
Whereas it has become easier for individuals to track their personal health data (e.g., heart rate, step count, food log), there is still a wide chasm between the collection of data and the generation of meaningful explanations to help users better understand what their data means to them. With an increased comprehension of their data, users will be able to act upon the newfound information and work towards striving closer to their health goals. We aim to bridge the gap between data collection and explanation generation by mining the data for interesting behavioral findings that may provide hints about a user's tendencies. Our focus is on improving the explainability of temporal personal health data via a set of informative summary templates, or "protoforms." These protoforms span both evaluation-based summaries that help users evaluate their health goals and pattern-based summaries that explain their implicit behaviors. In addition to individual users, the protoforms we use are also designed for population-level summaries. We apply our approach to generate summaries (both univariate and multivariate) from real user data and show that our system can generate interesting and useful explanations.
Learning Patient Engagement in Care Management: Performance vs. Interpretability
Jun 19, 2019
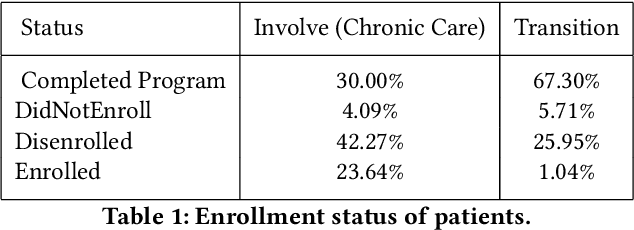
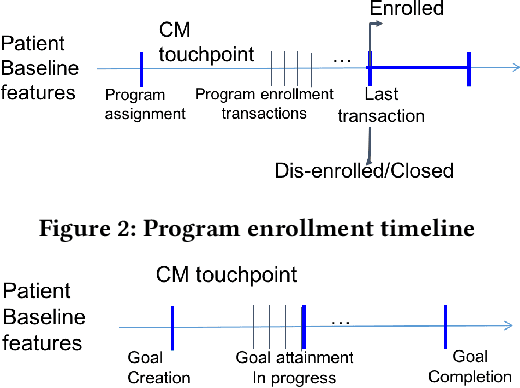
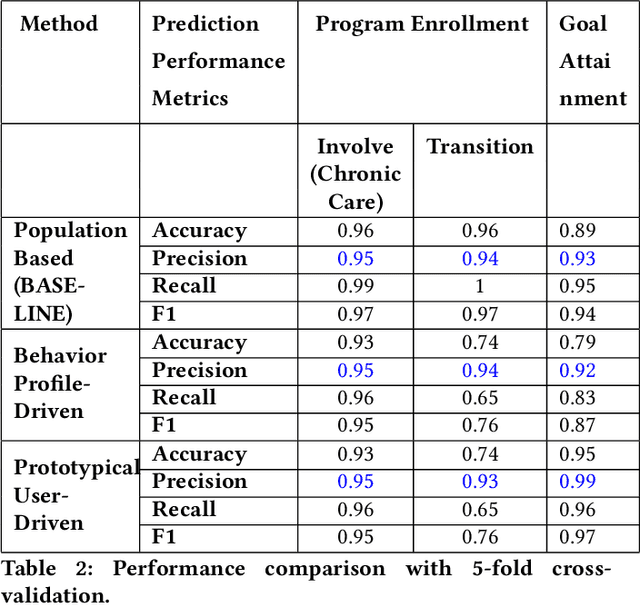
The health outcomes of high-need patients can be substantially influenced by the degree of patient engagement in their own care. The role of care managers includes that of enrolling patients into care programs and keeping them sufficiently engaged in the program, so that patients can attain various goals. The attainment of these goals is expected to improve the patients' health outcomes. In this paper, we present a real world data-driven method and the behavioral engagement scoring pipeline for scoring the engagement level of a patient in two regards: (1) Their interest in enrolling into a relevant care program, and (2) their interest and commitment to program goals. We use this score to predict a patient's propensity to respond (i.e., to a call for enrollment into a program, or to an assigned program goal). Using real-world care management data, we show that our scoring method successfully predicts patient engagement. We also show that we are able to provide interpretable insights to care managers, using prototypical patients as a point of reference, without sacrificing prediction performance.