 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-efficient Knowledge-based Question Answering with Large Language Models
Paper and Code
May 27, 2024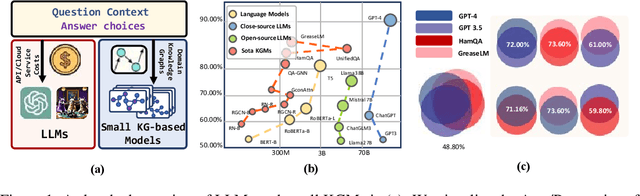
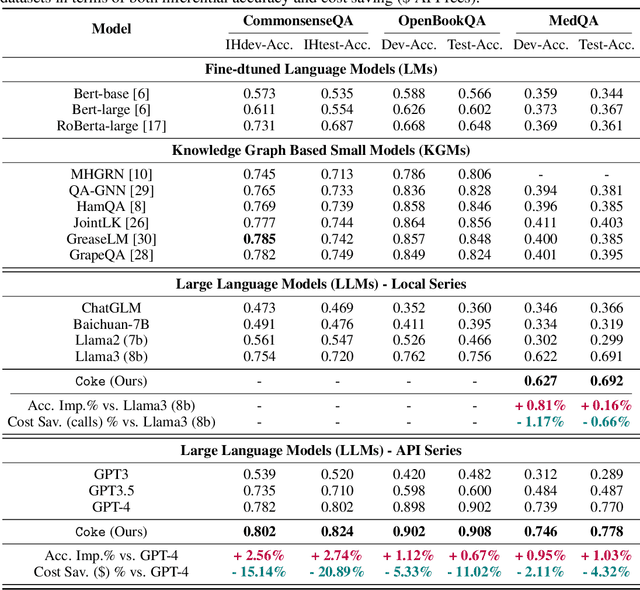
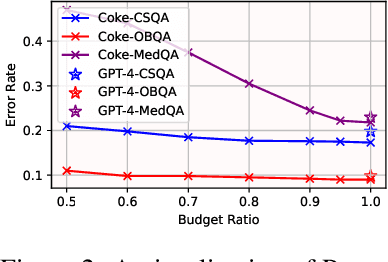
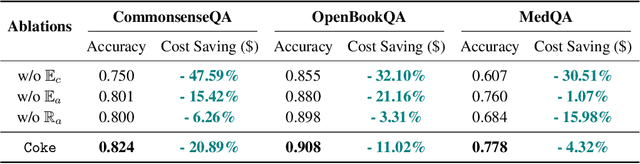
Knowledge-based question answering (KBQA) is widely used in many scenarios that necessitate domain knowledge. Large language models (LLMs) bring opportunities to KBQA, while their costs are significantly higher and absence of domain-specific knowledge during pre-training. We are motivated to combine LLMs and prior small models on knowledge graphs (KGMs) for both inferential accuracy and cost saving. However, it remains challenging since accuracy and cost are not readily combined in the optimization as two distinct metrics. It is also laborious for model selection since different models excel in diverse knowledge. To this end, we propose Coke, a novel cost-efficient strategy for KBQA with LLMs, modeled as a tailored multi-armed bandit problem to minimize calls to LLMs within limited budgets. We first formulate the accuracy expectation with a cluster-level Thompson Sampling for either KGMs or LLMs. A context-aware policy is optimized to further distinguish the expert model subject to the question semantics. The overall decision is bounded by the cost regret according to historical expenditure on failures. Extensive experiments showcase the superior performance of Coke, which moves the Pareto frontier with up to 20.89% saving of GPT-4 fees while achieving a 2.74% higher accuracy on the benchmark datasets.