 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Paper and Code
Jun 12, 2024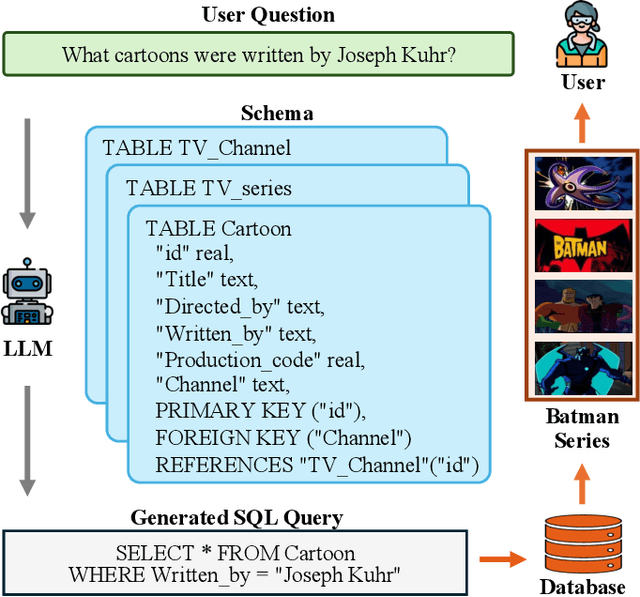

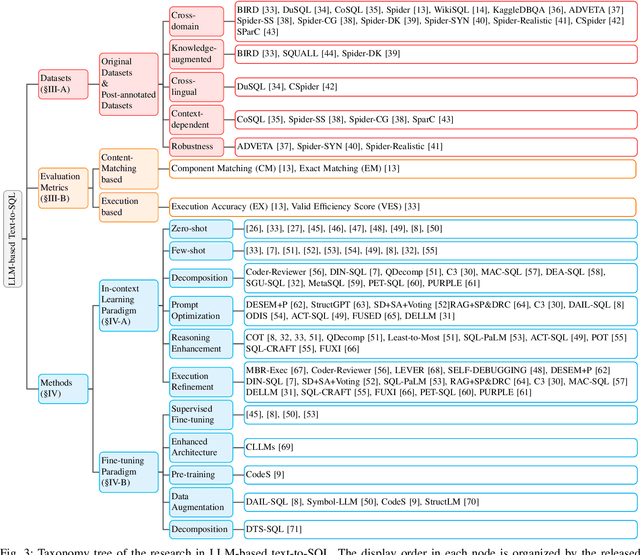
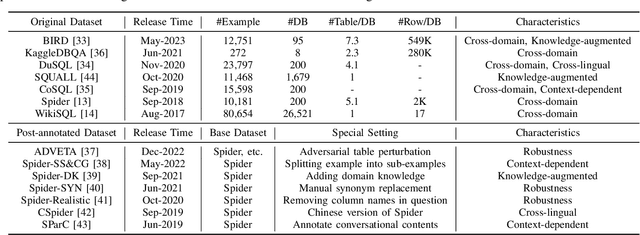
Generating accurate SQL according to natural language questions (text-to-SQL) is a long-standing problem since it is challenging in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems include human engineering and deep neural networks. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex and corresponding user questions more challenging, PLMs with limited comprehension capabilities can lead to incorrect SQL generation. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Most recently, large language models (LLMs) have demonstrated significant abilities in natural language understanding as the model scale remains increasing. Therefore, integrating the LLM-based implementation can bring unique opportunities, challenges, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the current challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future directions.