 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Layer-wise Approximation Rates for Deep Networks
Apr 22, 2026Depth is widely viewed as a central contributor to the success of deep neural networks, whereas standard neural network approximation theory typically provides guarantees only for the final output and leaves the role of intermediate layers largely unclear. We address this gap by developing a quantitative framework in which depth admits a precise scale-dependent interpretation. Specifically, we design a single shared mixed-activation architecture of fixed width $2dN+d+2$ and any prescribed finite depth such that each intermediate readout $Φ_\ell$ is itself an approximant to the target function $f$. For $f\in L^p([0,1]^d)$ with $p\in [1,\infty)$, the approximation error of $Φ_\ell$ is controlled by $(2d+1)$ times the $L^p$ modulus of continuity at the geometric scale $N^{-\ell}$ for all $\ell$. The estimate reduces to the geometric rate $(2d+1)N^{-\ell}$ if $f$ is $1$-Lipschitz. Our network design is inspired by multigrade deep learning, where depth serves as a progressive refinement mechanism: each new correction targets residual information at a finer scale while the earlier correction terms remain part of the later readouts, yielding a nested architecture that supports adaptive refinement without redesigning the preceding network.
Deep learning and the rate of approximation by flows
Mar 16, 2026We investigate the dependence of the approximation capacity of deep residual networks on its depth in a continuous dynamical systems setting. This can be formulated as the general problem of quantifying the minimal time-horizon required to approximate a diffeomorphism by flows driven by a given family $\mathcal F$ of vector fields. We show that this minimal time can be identified as a geodesic distance on a sub-Finsler manifold of diffeomorphisms, where the local geometry is characterised by a variational principle involving $\mathcal F$. This connects the learning efficiency of target relationships to their compatibility with the learning architectural choice. Further, the results suggest that the key approximation mechanism in deep learning, namely the approximation of functions by composition or dynamics, differs in a fundamental way from linear approximation theory, where linear spaces and norm-based rate estimates are replaced by manifolds and geodesic distances.
Multigrade Neural Network Approximation
Jan 23, 2026We study multigrade deep learning (MGDL) as a principled framework for structured error refinement in deep neural networks. While the approximation power of neural networks is now relatively well understood, training very deep architectures remains challenging due to highly non-convex and often ill-conditioned optimization landscapes. In contrast, for relatively shallow networks, most notably one-hidden-layer $\texttt{ReLU}$ models, training admits convex reformulations with global guarantees, motivating learning paradigms that improve stability while scaling to depth. MGDL builds upon this insight by training deep networks grade by grade: previously learned grades are frozen, and each new residual block is trained solely to reduce the remaining approximation error, yielding an interpretable and stable hierarchical refinement process. We develop an operator-theoretic foundation for MGDL and prove that, for any continuous target function, there exists a fixed-width multigrade $\texttt{ReLU}$ scheme whose residuals decrease strictly across grades and converge uniformly to zero. To the best of our knowledge, this work provides the first rigorous theoretical guarantee that grade-wise training yields provable vanishing approximation error in deep networks. Numerical experiments further illustrate the theoretical results.
Enhancing Low-resolution Image Representation Through Normalizing Flows
Jan 11, 2026Low-resolution image representation is a special form of sparse representation that retains only low-frequency information while discarding high-frequency components. This property reduces storage and transmission costs and benefits various image processing tasks. However, a key challenge is to preserve essential visual content while maintaining the ability to accurately reconstruct the original images. This work proposes LR2Flow, a nonlinear framework that learns low-resolution image representations by integrating wavelet tight frame blocks with normalizing flows. We conduct a reconstruction error analysis of the proposed network, which demonstrates the necessity of designing invertible neural networks in the wavelet tight frame domain. Experimental results on various tasks, including image rescaling, compression, and denoising, demonstrate the effectiveness of the learned representations and the robustness of the proposed framework.
Interpolation, Approximation and Controllability of Deep Neural Networks
Sep 12, 2023We investigate the expressive power of deep residual neural networks idealized as continuous dynamical systems through control theory. Specifically, we consider two properties that arise from supervised learning, namely universal interpolation - the ability to match arbitrary input and target training samples - and the closely related notion of universal approximation - the ability to approximate input-target functional relationships via flow maps. Under the assumption of affine invariance of the control family, we give a characterisation of universal interpolation, showing that it holds for essentially any architecture with non-linearity. Furthermore, we elucidate the relationship between universal interpolation and universal approximation in the context of general control systems, showing that the two properties cannot be deduced from each other. At the same time, we identify conditions on the control family and the target function that ensures the equivalence of the two notions.
On the Universal Approximation Property of Deep Fully Convolutional Neural Networks
Nov 25, 2022
We study the approximation of shift-invariant or equivariant functions by deep fully convolutional networks from the dynamical systems perspective. We prove that deep residual fully convolutional networks and their continuous-layer counterpart can achieve universal approximation of these symmetric functions at constant channel width. Moreover, we show that the same can be achieved by non-residual variants with at least 2 channels in each layer and convolutional kernel size of at least 2. In addition, we show that these requirements are necessary, in the sense that networks with fewer channels or smaller kernels fail to be universal approximators.
Deep Neural Network Approximation of Invariant Functions through Dynamical Systems
Aug 18, 2022
We study the approximation of functions which are invariant with respect to certain permutations of the input indices using flow maps of dynamical systems. Such invariant functions includes the much studied translation-invariant ones involving image tasks, but also encompasses many permutation-invariant functions that finds emerging applications in science and engineering. We prove sufficient conditions for universal approximation of these functions by a controlled equivariant dynamical system, which can be viewed as a general abstraction of deep residual networks with symmetry constraints. These results not only imply the universal approximation for a variety of commonly employed neural network architectures for symmetric function approximation, but also guide the design of architectures with approximation guarantees for applications involving new symmetry requirements.
Neural Network Architecture Beyond Width and Depth
May 19, 2022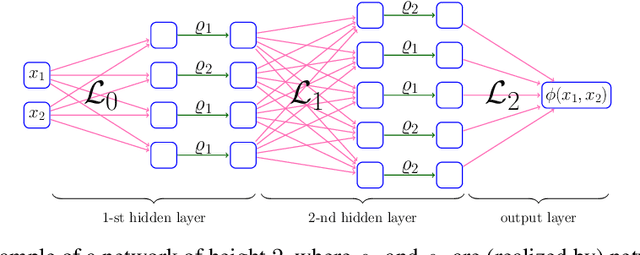

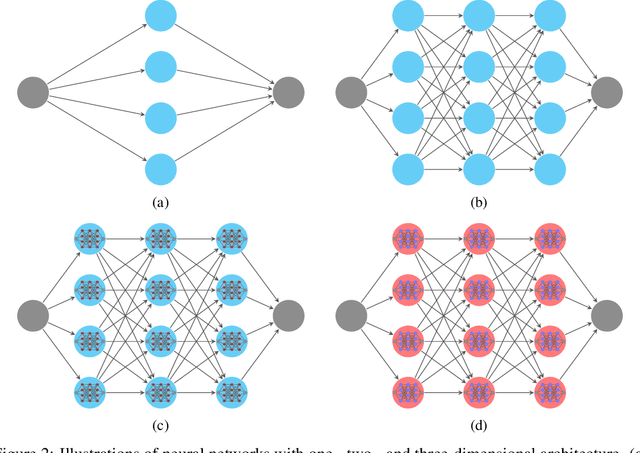
This paper proposes a new neural network architecture by introducing an additional dimension called height beyond width and depth. Neural network architectures with height, width, and depth as hyperparameters are called three-dimensional architectures. It is shown that neural networks with three-dimensional architectures are significantly more expressive than the ones with two-dimensional architectures (those with only width and depth as hyperparameters), e.g., standard fully connected networks. The new network architecture is constructed recursively via a nested structure, and hence we call a network with the new architecture nested network (NestNet). A NestNet of height $s$ is built with each hidden neuron activated by a NestNet of height $\le s-1$. When $s=1$, a NestNet degenerates to a standard network with a two-dimensional architecture. It is proved by construction that height-$s$ ReLU NestNets with $\mathcal{O}(n)$ parameters can approximate Lipschitz continuous functions on $[0,1]^d$ with an error $\mathcal{O}(n^{-(s+1)/d})$, while the optimal approximation error of standard ReLU networks with $\mathcal{O}(n)$ parameters is $\mathcal{O}(n^{-2/d})$. Furthermore, such a result is extended to generic continuous functions on $[0,1]^d$ with the approximation error characterized by the modulus of continuity. Finally, a numerical example is provided to explore the advantages of the super approximation power of ReLU NestNets.
IAE-Net: Integral Autoencoders for Discretization-Invariant Learning
Mar 30, 2022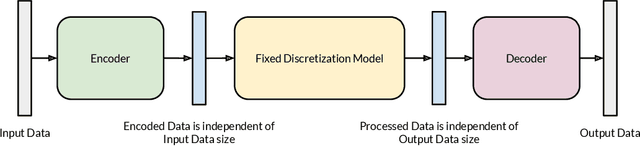

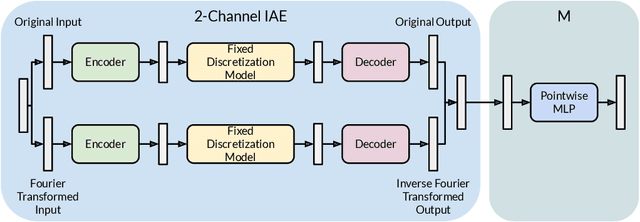

Discretization invariant learning aims at learning in the infinite-dimensional function spaces with the capacity to process heterogeneous discrete representations of functions as inputs and/or outputs of a learning model. This paper proposes a novel deep learning framework based on integral autoencoders (IAE-Net) for discretization invariant learning. The basic building block of IAE-Net consists of an encoder and a decoder as integral transforms with data-driven kernels, and a fully connected neural network between the encoder and decoder. This basic building block is applied in parallel in a wide multi-channel structure, which are repeatedly composed to form a deep and densely connected neural network with skip connections as IAE-Net. IAE-Net is trained with randomized data augmentation that generates training data with heterogeneous structures to facilitate the performance of discretization invariant learning. The proposed IAE-Net is tested with various applications in predictive data science, solving forward and inverse problems in scientific computing, and signal/image processing. Compared with alternatives in the literature, IAE-Net achieves state-of-the-art performance in existing applications and creates a wide range of new applications.
ReLU Network Approximation in Terms of Intrinsic Parameters
Nov 15, 2021
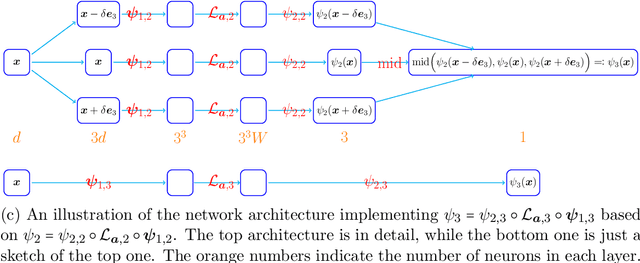
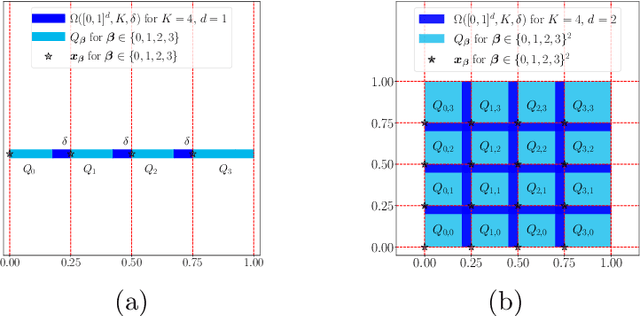
This paper studies the approximation error of ReLU networks in terms of the number of intrinsic parameters (i.e., those depending on the target function $f$). First, we prove by construction that, for any Lipschitz continuous function $f$ on $[0,1]^d$ with a Lipschitz constant $\lambda>0$, a ReLU network with $n+2$ intrinsic parameters can approximate $f$ with an exponentially small error $5\lambda \sqrt{d}\,2^{-n}$ measured in the $L^p$-norm for $p\in [1,\infty)$. More generally for an arbitrary continuous function $f$ on $[0,1]^d$ with a modulus of continuity $\omega_f(\cdot)$, the approximation error is $\omega_f(\sqrt{d}\, 2^{-n})+2^{-n+2}\omega_f(\sqrt{d})$. Next, we extend these two results from the $L^p$-norm to the $L^\infty$-norm at a price of $3^d n+2$ intrinsic parameters. Finally, by using a high-precision binary representation and the bit extraction technique via a fixed ReLU network independent of the target function, we design, theoretically, a ReLU network with only three intrinsic parameters to approximate H\"older continuous functions with an arbitrarily small error.