 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Approximation: Three Hidden Layers Are Enough
Paper and Code
Oct 25, 2020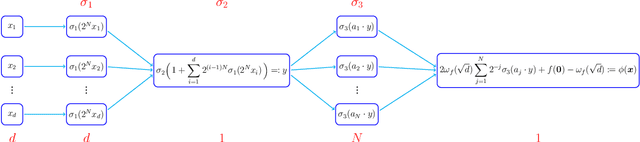


A three-hidden-layer neural network with super approximation power is introduced. This network is built with the Floor function ($\lfloor x\rfloor$), the exponential function ($2^x$), the step function ($\one_{x\geq 0}$), or their compositions as activation functions in each neuron and hence we call such networks as Floor-Exponential-Step (FLES) networks. For any width hyper-parameter $N\in\mathbb{N}^+$, it is shown that FLES networks with a width $\max\{d,\, N\}$ and three hidden layers can uniformly approximate a H{\"o}lder function $f$ on $[0,1]^d$ with an exponential approximation rate $3\lambda d^{\alpha/2}2^{-\alpha N}$, where $\alpha \in(0,1]$ and $\lambda$ are the H{\"o}lder order and constant, respectively. More generally for an arbitrary continuous function $f$ on $[0,1]^d$ with a modulus of continuity $\omega_f(\cdot)$, the constructive approximation rate is $\omega_f(\sqrt{d}\,2^{-N})+2\omega_f(\sqrt{d}){2^{-N}}$. As a consequence, this new {class of networks} overcomes the curse of dimensionality in approximation power when the variation of $\omega_f(r)$ as $r\rightarrow 0$ is moderate (e.g., $\omega_f(r){\lesssim} r^\alpha$ for H{\"o}lder continuous functions), since the major term to be concerned in our approximation rate is essentially $\sqrt{d}$ times a function of $N$ independent of $d$ within the modulus of continuity.