 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Approximation Rate of ReLU Networks in terms of Width and Depth
Paper and Code
Feb 28, 2021
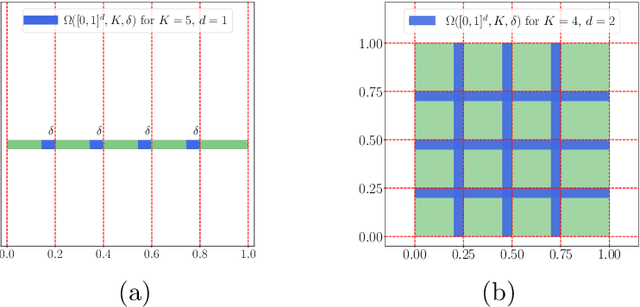
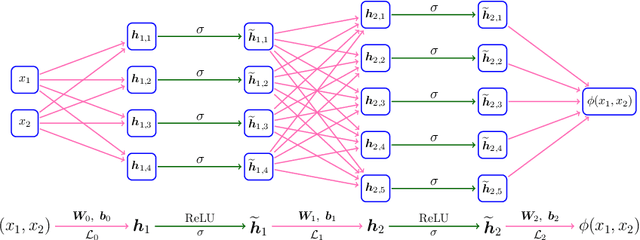
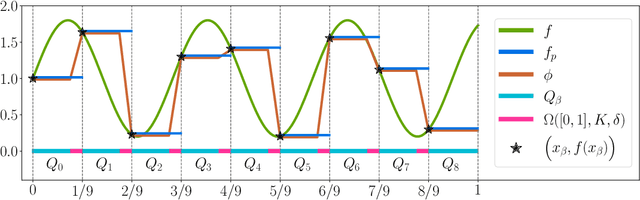
This paper concentrates on the approximation power of deep feed-forward neural networks in terms of width and depth. It is proved by construction that ReLU networks with width $\mathcal{O}\big(\max\{d\lfloor N^{1/d}\rfloor,\, N+2\}\big)$ and depth $\mathcal{O}(L)$ can approximate a H\"older continuous function on $[0,1]^d$ with an approximation rate $\mathcal{O}\big(\lambda\sqrt{d} (N^2L^2\ln N)^{-\alpha/d}\big)$, where $\alpha\in (0,1]$ and $\lambda>0$ are H\"older order and constant, respectively. Such a rate is optimal up to a constant in terms of width and depth separately, while existing results are only nearly optimal without the logarithmic factor in the approximation rate. More generally, for an arbitrary continuous function $f$ on $[0,1]^d$, the approximation rate becomes $\mathcal{O}\big(\,\sqrt{d}\,\omega_f\big( (N^2L^2\ln N)^{-1/d}\big)\,\big)$, where $\omega_f(\cdot)$ is the modulus of continuity. We also extend our analysis to any continuous function $f$ on a bounded set. Particularly, if ReLU networks with depth $31$ and width $\mathcal{O}(N)$ are used to approximate one-dimensional Lipschitz continuous functions on $[0,1]$ with a Lipschitz constant $\lambda>0$, the approximation rate in terms of the total number of parameters, $W=\mathcal{O}(N^2)$, becomes $\mathcal{O}(\tfrac{\lambda}{W\ln W})$, which has not been discovered in the literature for fixed-depth ReLU networks.