 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBACON: Bayesian Optimal Condensation Framework for Dataset Distillation
Paper and Code
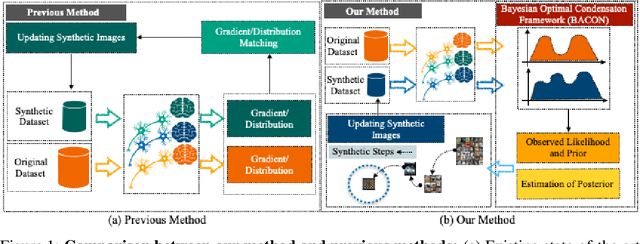
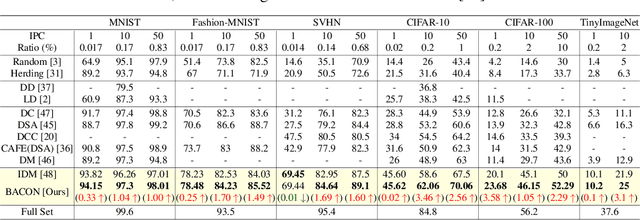
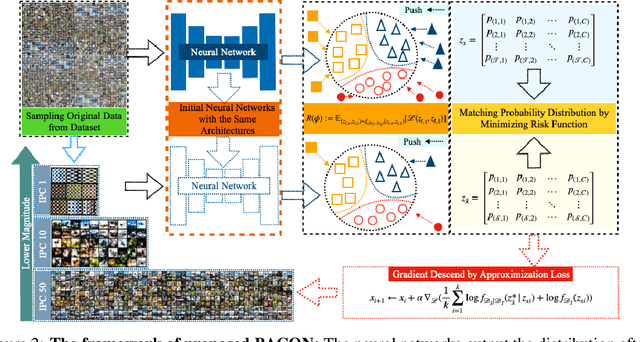
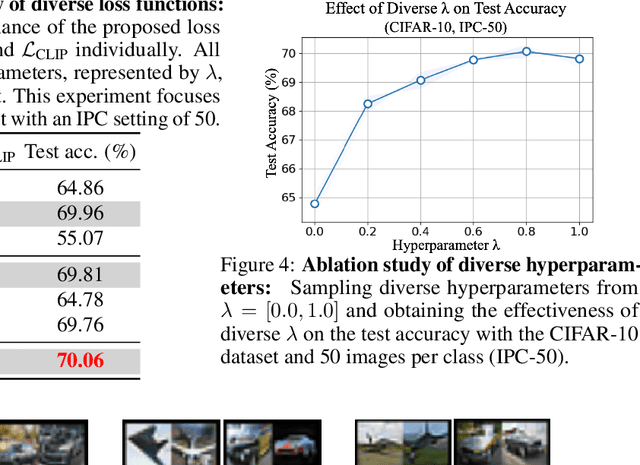
Dataset Distillation (DD) aims to distill knowledge from extensive datasets into more compact ones while preserving performance on the test set, thereby reducing storage costs and training expenses. However, existing methods often suffer from computational intensity, particularly exhibiting suboptimal performance with large dataset sizes due to the lack of a robust theoretical framework for analyzing the DD problem. To address these challenges, we propose the BAyesian optimal CONdensation framework (BACON), which is the first work to introduce the Bayesian theoretical framework to the literature of DD. This framework provides theoretical support for enhancing the performance of DD. Furthermore, BACON formulates the DD problem as the minimization of the expected risk function in joint probability distributions using the Bayesian framework. Additionally, by analyzing the expected risk function for optimal condensation, we derive a numerically feasible lower bound based on specific assumptions, providing an approximate solution for BACON. We validate BACON across several datasets, demonstrating its superior performance compared to existing state-of-the-art methods. For instance, under the IPC-10 setting, BACON achieves a 3.46% accuracy gain over the IDM method on the CIFAR-10 dataset and a 3.10% gain on the TinyImageNet dataset. Our extensive experiments confirm the effectiveness of BACON and its seamless integration with existing methods, thereby enhancing their performance for the DD task. Code and distilled datasets are available at BACON.