 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Domain Generalization via Universe Learning: A Multi-Graph Matching Approach for Medical Image Segmentation
Mar 17, 2025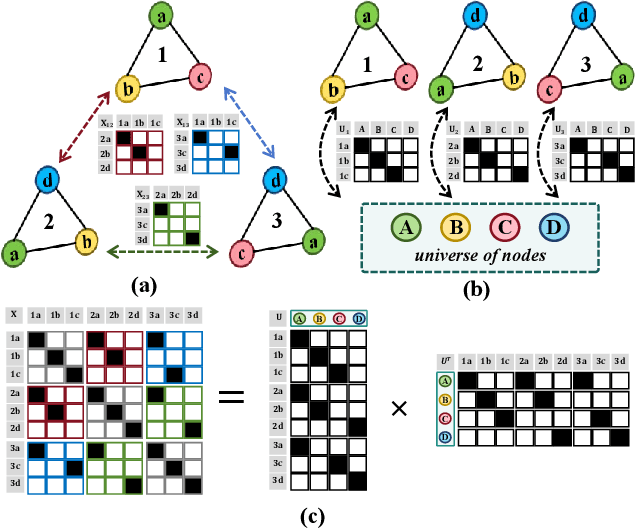

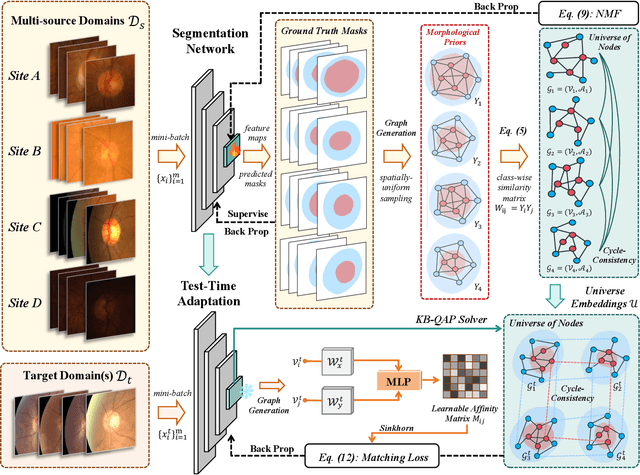

Despite domain generalization (DG) has significantly addressed the performance degradation of pre-trained models caused by domain shifts, it often falls short in real-world deployment. Test-time adaptation (TTA), which adjusts a learned model using unlabeled test data, presents a promising solution. However, most existing TTA methods struggle to deliver strong performance in medical image segmentation, primarily because they overlook the crucial prior knowledge inherent to medical images. To address this challenge, we incorporate morphological information and propose a framework based on multi-graph matching. Specifically, we introduce learnable universe embeddings that integrate morphological priors during multi-source training, along with novel unsupervised test-time paradigms for domain adaptation. This approach guarantees cycle-consistency in multi-matching while enabling the model to more effectively capture the invariant priors of unseen data, significantly mitigating the effects of domain shifts. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches on two medical image segmentation benchmarks for both multi-source and single-source domain generalization tasks. The source code is available at https://github.com/Yore0/TTDG-MGM.
Multiscale Progressive Text Prompt Network for Medical Image Segmentation
Jun 30, 2023The accurate segmentation of medical images is a crucial step in obtaining reliable morphological statistics. However, training a deep neural network for this task requires a large amount of labeled data to ensure high-accuracy results. To address this issue, we propose using progressive text prompts as prior knowledge to guide the segmentation process. Our model consists of two stages. In the first stage, we perform contrastive learning on natural images to pretrain a powerful prior prompt encoder (PPE). This PPE leverages text prior prompts to generate multimodality features. In the second stage, medical image and text prior prompts are sent into the PPE inherited from the first stage to achieve the downstream medical image segmentation task. A multiscale feature fusion block (MSFF) combines the features from the PPE to produce multiscale multimodality features. These two progressive features not only bridge the semantic gap but also improve prediction accuracy. Finally, an UpAttention block refines the predicted results by merging the image and text features. This design provides a simple and accurate way to leverage multiscale progressive text prior prompts for medical image segmentation. Compared with using only images, our model achieves high-quality results with low data annotation costs. Moreover, our model not only has excellent reliability and validity on medical images but also performs well on natural images. The experimental results on different image datasets demonstrate that our model is effective and robust for image segmentation.
Unsupervised Video Segmentation via Spatio-Temporally Nonlocal Appearance Learning
Dec 24, 2016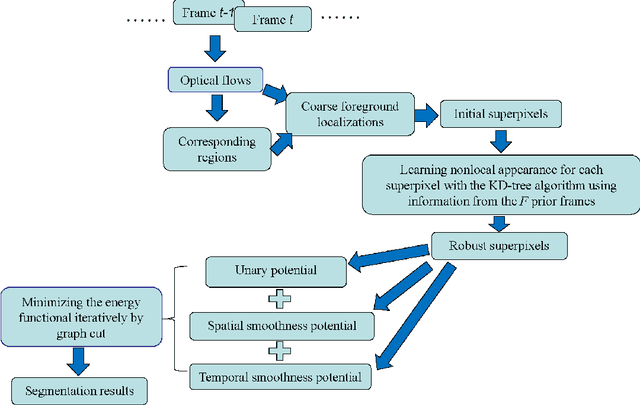


Video object segmentation is challenging due to the factors like rapidly fast motion, cluttered backgrounds, arbitrary object appearance variation and shape deformation. Most existing methods only explore appearance information between two consecutive frames, which do not make full use of the usefully long-term nonlocal information that is helpful to make the learned appearance stable, and hence they tend to fail when the targets suffer from large viewpoint changes and significant non-rigid deformations. In this paper, we propose a simple yet effective approach to mine the long-term sptatio-temporally nonlocal appearance information for unsupervised video segmentation. The motivation of our algorithm comes from the spatio-temporal nonlocality of the region appearance reoccurrence in a video. Specifically, we first generate a set of superpixels to represent the foreground and background, and then update the appearance of each superpixel with its long-term sptatio-temporally nonlocal counterparts generated by the approximate nearest neighbor search method with the efficient KD-tree algorithm. Then, with the updated appearances, we formulate a spatio-temporal graphical model comprised of the superpixel label consistency potentials. Finally, we generate the segmentation by optimizing the graphical model via iteratively updating the appearance model and estimating the labels. Extensive evaluations on the SegTrack and Youtube-Objects datasets demonstrate the effectiveness of the proposed method, which performs favorably against some state-of-art methods.