 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPUS: Occupancy Prediction Using a Sparse Set
Sep 14, 2024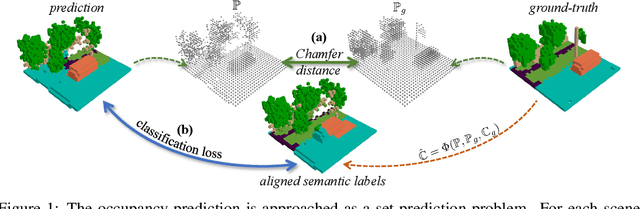
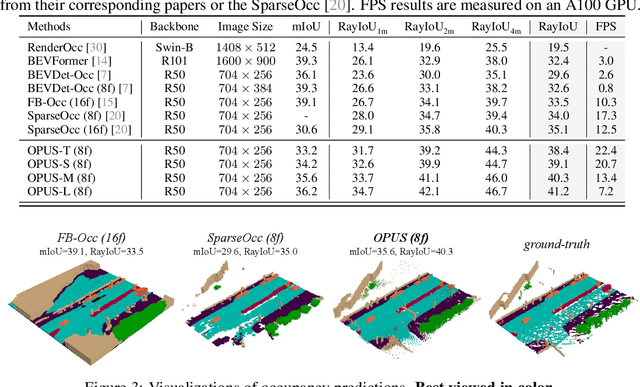
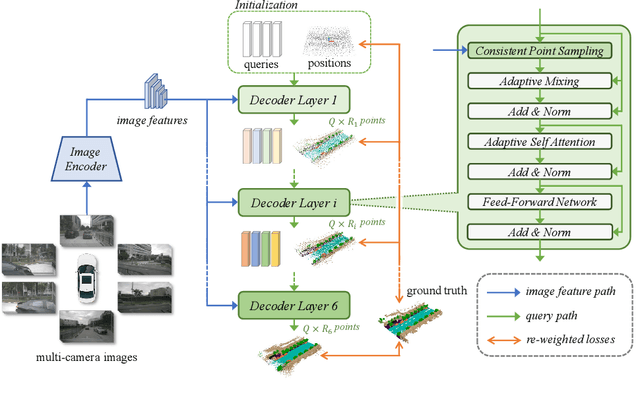
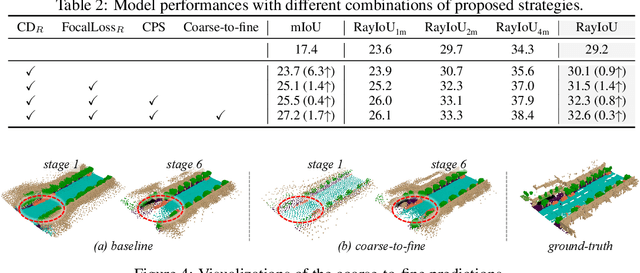
Occupancy prediction, aiming at predicting the occupancy status within voxelized 3D environment, is quickly gaining momentum within the autonomous driving community. Mainstream occupancy prediction works first discretize the 3D environment into voxels, then perform classification on such dense grids. However, inspection on sample data reveals that the vast majority of voxels is unoccupied. Performing classification on these empty voxels demands suboptimal computation resource allocation, and reducing such empty voxels necessitates complex algorithm designs. To this end, we present a novel perspective on the occupancy prediction task: formulating it as a streamlined set prediction paradigm without the need for explicit space modeling or complex sparsification procedures. Our proposed framework, called OPUS, utilizes a transformer encoder-decoder architecture to simultaneously predict occupied locations and classes using a set of learnable queries. Firstly, we employ the Chamfer distance loss to scale the set-to-set comparison problem to unprecedented magnitudes, making training such model end-to-end a reality. Subsequently, semantic classes are adaptively assigned using nearest neighbor search based on the learned locations. In addition, OPUS incorporates a suite of non-trivial strategies to enhance model performance, including coarse-to-fine learning, consistent point sampling, and adaptive re-weighting, etc. Finally, compared with current state-of-the-art methods, our lightest model achieves superior RayIoU on the Occ3D-nuScenes dataset at near 2x FPS, while our heaviest model surpasses previous best results by 6.1 RayIoU.
Towards Stable 3D Object Detection
Jul 05, 2024



In autonomous driving, the temporal stability of 3D object detection greatly impacts the driving safety. However, the detection stability cannot be accessed by existing metrics such as mAP and MOTA, and consequently is less explored by the community. To bridge this gap, this work proposes Stability Index (SI), a new metric that can comprehensively evaluate the stability of 3D detectors in terms of confidence, box localization, extent, and heading. By benchmarking state-of-the-art object detectors on the Waymo Open Dataset, SI reveals interesting properties of object stability that have not been previously discovered by other metrics. To help models improve their stability, we further introduce a general and effective training strategy, called Prediction Consistency Learning (PCL). PCL essentially encourages the prediction consistency of the same objects under different timestamps and augmentations, leading to enhanced detection stability. Furthermore, we examine the effectiveness of PCL with the widely-used CenterPoint, and achieve a remarkable SI of 86.00 for vehicle class, surpassing the baseline by 5.48. We hope our work could serve as a reliable baseline and draw the community's attention to this crucial issue in 3D object detection. Codes will be made publicly available.
Small, Versatile and Mighty: A Range-View Perception Framework
Mar 01, 2024Despite its compactness and information integrity, the range view representation of LiDAR data rarely occurs as the first choice for 3D perception tasks. In this work, we further push the envelop of the range-view representation with a novel multi-task framework, achieving unprecedented 3D detection performances. Our proposed Small, Versatile, and Mighty (SVM) network utilizes a pure convolutional architecture to fully unleash the efficiency and multi-tasking potentials of the range view representation. To boost detection performances, we first propose a range-view specific Perspective Centric Label Assignment (PCLA) strategy, and a novel View Adaptive Regression (VAR) module to further refine hard-to-predict box properties. In addition, our framework seamlessly integrates semantic segmentation and panoptic segmentation tasks for the LiDAR point cloud, without extra modules. Among range-view-based methods, our model achieves new state-of-the-art detection performances on the Waymo Open Dataset. Especially, over 10 mAP improvement over convolutional counterparts can be obtained on the vehicle class. Our presented results for other tasks further reveal the multi-task capabilities of the proposed small but mighty framework.
Curricular Object Manipulation in LiDAR-based Object Detection
Apr 09, 2023



This paper explores the potential of curriculum learning in LiDAR-based 3D object detection by proposing a curricular object manipulation (COM) framework. The framework embeds the curricular training strategy into both the loss design and the augmentation process. For the loss design, we propose the COMLoss to dynamically predict object-level difficulties and emphasize objects of different difficulties based on training stages. On top of the widely-used augmentation technique called GT-Aug in LiDAR detection tasks, we propose a novel COMAug strategy which first clusters objects in ground-truth database based on well-designed heuristics. Group-level difficulties rather than individual ones are then predicted and updated during training for stable results. Model performance and generalization capabilities can be improved by sampling and augmenting progressively more difficult objects into the training samples. Extensive experiments and ablation studies reveal the superior and generality of the proposed framework. The code is available at https://github.com/ZZY816/COM.