 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlinePG: Online Open-Vocabulary Panoptic Mapping with 3D Gaussian Splatting
Mar 19, 2026Open-vocabulary scene understanding with online panoptic mapping is essential for embodied applications to perceive and interact with environments. However, existing methods are predominantly offline or lack instance-level understanding, limiting their applicability to real-world robotic tasks. In this paper, we propose OnlinePG, a novel and effective system that integrates geometric reconstruction and open-vocabulary perception using 3D Gaussian Splatting in an online setting. Technically, to achieve online panoptic mapping, we employ an efficient local-to-global paradigm with a sliding window. To build local consistency map, we construct a 3D segment clustering graph that jointly leverages geometric and semantic cues, fusing inconsistent segments within sliding window into complete instances. Subsequently, to update the global map, we construct explicit grids with spatial attributes for the local 3D Gaussian map and fuse them into the global map via robust bidirectional bipartite 3D Gaussian instance matching. Finally, we utilize the fused VLM features inside the 3D spatial attribute grids to achieve open-vocabulary scene understanding. Extensive experiments on widely used datasets demonstrate that our method achieves better performance among online approaches, while maintaining real-time efficiency.
One-Shot Refiner: Boosting Feed-forward Novel View Synthesis via One-Step Diffusion
Jan 20, 2026We present a novel framework for high-fidelity novel view synthesis (NVS) from sparse images, addressing key limitations in recent feed-forward 3D Gaussian Splatting (3DGS) methods built on Vision Transformer (ViT) backbones. While ViT-based pipelines offer strong geometric priors, they are often constrained by low-resolution inputs due to computational costs. Moreover, existing generative enhancement methods tend to be 3D-agnostic, resulting in inconsistent structures across views, especially in unseen regions. To overcome these challenges, we design a Dual-Domain Detail Perception Module, which enables handling high-resolution images without being limited by the ViT backbone, and endows Gaussians with additional features to store high-frequency details. We develop a feature-guided diffusion network, which can preserve high-frequency details during the restoration process. We introduce a unified training strategy that enables joint optimization of the ViT-based geometric backbone and the diffusion-based refinement module. Experiments demonstrate that our method can maintain superior generation quality across multiple datasets.
OMGSR: You Only Need One Mid-timestep Guidance for Real-World Image Super-Resolution
Aug 11, 2025Denoising Diffusion Probabilistic Models (DDPM) and Flow Matching (FM) generative models show promising potential for one-step Real-World Image Super-Resolution (Real-ISR). Recent one-step Real-ISR models typically inject a Low-Quality (LQ) image latent distribution at the initial timestep. However, a fundamental gap exists between the LQ image latent distribution and the Gaussian noisy latent distribution, limiting the effective utilization of generative priors. We observe that the noisy latent distribution at DDPM/FM mid-timesteps aligns more closely with the LQ image latent distribution. Based on this insight, we present One Mid-timestep Guidance Real-ISR (OMGSR), a universal framework applicable to DDPM/FM-based generative models. OMGSR injects the LQ image latent distribution at a pre-computed mid-timestep, incorporating the proposed Latent Distribution Refinement loss to alleviate the latent distribution gap. We also design the Overlap-Chunked LPIPS/GAN loss to eliminate checkerboard artifacts in image generation. Within this framework, we instantiate OMGSR for DDPM/FM-based generative models with two variants: OMGSR-S (SD-Turbo) and OMGSR-F (FLUX.1-dev). Experimental results demonstrate that OMGSR-S/F achieves balanced/excellent performance across quantitative and qualitative metrics at 512-resolution. Notably, OMGSR-F establishes overwhelming dominance in all reference metrics. We further train a 1k-resolution OMGSR-F to match the default resolution of FLUX.1-dev, which yields excellent results, especially in the details of the image generation. We also generate 2k-resolution images by the 1k-resolution OMGSR-F using our two-stage Tiled VAE & Diffusion.
BokehDiff: Neural Lens Blur with One-Step Diffusion
Jul 24, 2025We introduce BokehDiff, a novel lens blur rendering method that achieves physically accurate and visually appealing outcomes, with the help of generative diffusion prior. Previous methods are bounded by the accuracy of depth estimation, generating artifacts in depth discontinuities. Our method employs a physics-inspired self-attention module that aligns with the image formation process, incorporating depth-dependent circle of confusion constraint and self-occlusion effects. We adapt the diffusion model to the one-step inference scheme without introducing additional noise, and achieve results of high quality and fidelity. To address the lack of scalable paired data, we propose to synthesize photorealistic foregrounds with transparency with diffusion models, balancing authenticity and scene diversity.
HyperMotion: DiT-Based Pose-Guided Human Image Animation of Complex Motions
May 29, 2025Recent advances in diffusion models have significantly improved conditional video generation, particularly in the pose-guided human image animation task. Although existing methods are capable of generating high-fidelity and time-consistent animation sequences in regular motions and static scenes, there are still obvious limitations when facing complex human body motions (Hypermotion) that contain highly dynamic, non-standard motions, and the lack of a high-quality benchmark for evaluation of complex human motion animations. To address this challenge, we introduce the \textbf{Open-HyperMotionX Dataset} and \textbf{HyperMotionX Bench}, which provide high-quality human pose annotations and curated video clips for evaluating and improving pose-guided human image animation models under complex human motion conditions. Furthermore, we propose a simple yet powerful DiT-based video generation baseline and design spatial low-frequency enhanced RoPE, a novel module that selectively enhances low-frequency spatial feature modeling by introducing learnable frequency scaling. Our method significantly improves structural stability and appearance consistency in highly dynamic human motion sequences. Extensive experiments demonstrate the effectiveness of our dataset and proposed approach in advancing the generation quality of complex human motion image animations. Code and dataset will be made publicly available.
CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models
Dec 17, 2024



Text-to-image diffusion models excel at generating photorealistic images, but commonly struggle to render accurate spatial relationships described in text prompts. We identify two core issues underlying this common failure: 1) the ambiguous nature of spatial-related data in existing datasets, and 2) the inability of current text encoders to accurately interpret the spatial semantics of input descriptions. We address these issues with CoMPaSS, a versatile training framework that enhances spatial understanding of any T2I diffusion model. CoMPaSS solves the ambiguity of spatial-related data with the Spatial Constraints-Oriented Pairing (SCOP) data engine, which curates spatially-accurate training data through a set of principled spatial constraints. To better exploit the curated high-quality spatial priors, CoMPaSS further introduces a Token ENcoding ORdering (TENOR) module to allow better exploitation of high-quality spatial priors, effectively compensating for the shortcoming of text encoders. Extensive experiments on four popular open-weight T2I diffusion models covering both UNet- and MMDiT-based architectures demonstrate the effectiveness of CoMPaSS by setting new state-of-the-arts with substantial relative gains across well-known benchmarks on spatial relationships generation, including VISOR (+98%), T2I-CompBench Spatial (+67%), and GenEval Position (+131%). Code will be available at https://github.com/blurgyy/CoMPaSS.
DiverGen: Improving Instance Segmentation by Learning Wider Data Distribution with More Diverse Generative Data
May 16, 2024Instance segmentation is data-hungry, and as model capacity increases, data scale becomes crucial for improving the accuracy. Most instance segmentation datasets today require costly manual annotation, limiting their data scale. Models trained on such data are prone to overfitting on the training set, especially for those rare categories. While recent works have delved into exploiting generative models to create synthetic datasets for data augmentation, these approaches do not efficiently harness the full potential of generative models. To address these issues, we introduce a more efficient strategy to construct generative datasets for data augmentation, termed DiverGen. Firstly, we provide an explanation of the role of generative data from the perspective of distribution discrepancy. We investigate the impact of different data on the distribution learned by the model. We argue that generative data can expand the data distribution that the model can learn, thus mitigating overfitting. Additionally, we find that the diversity of generative data is crucial for improving model performance and enhance it through various strategies, including category diversity, prompt diversity, and generative model diversity. With these strategies, we can scale the data to millions while maintaining the trend of model performance improvement. On the LVIS dataset, DiverGen significantly outperforms the strong model X-Paste, achieving +1.1 box AP and +1.1 mask AP across all categories, and +1.9 box AP and +2.5 mask AP for rare categories.
Guided Colorization Using Mono-Color Image Pairs
Aug 17, 2021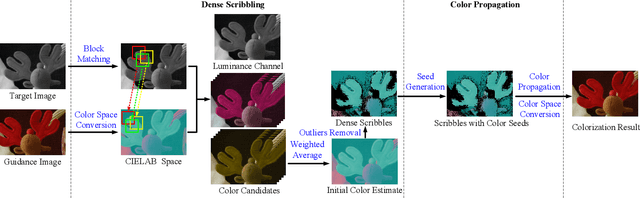
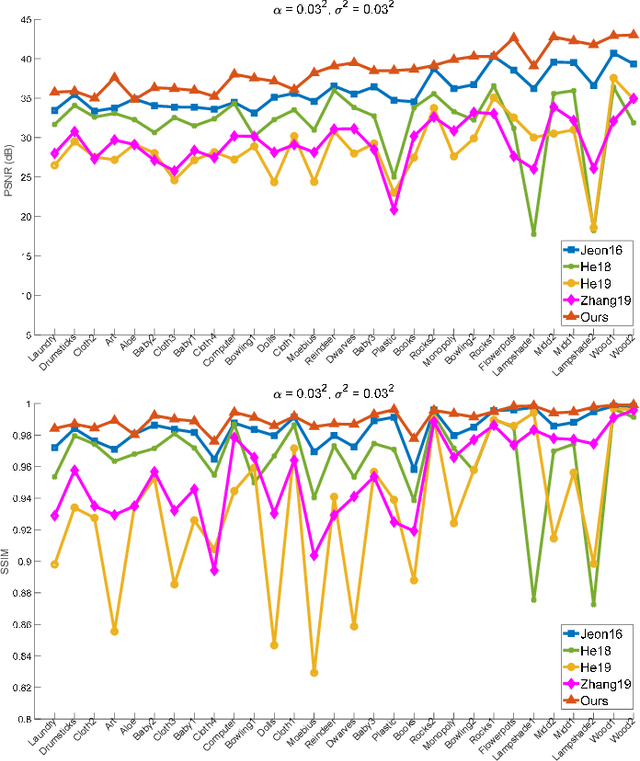


Compared to color images captured by conventional RGB cameras, monochrome images usually have better signal-to-noise ratio (SNR) and richer textures due to its higher quantum efficiency. It is thus natural to apply a mono-color dual-camera system to restore color images with higher visual quality. In this paper, we propose a mono-color image enhancement algorithm that colorizes the monochrome image with the color one. Based on the assumption that adjacent structures with similar luminance values are likely to have similar colors, we first perform dense scribbling to assign colors to the monochrome pixels through block matching. Two types of outliers, including occlusion and color ambiguity, are detected and removed from the initial scribbles. We also introduce a sampling strategy to accelerate the scribbling process. Then, the dense scribbles are propagated to the entire image. To alleviate incorrect color propagation in the regions that have no color hints at all, we generate extra color seeds based on the existed scribbles to guide the propagation process. Experimental results show that, our algorithm can efficiently restore color images with higher SNR and richer details from the mono-color image pairs, and achieves good performance in solving the color bleeding problem.