 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.
CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models
Dec 17, 2024



Text-to-image diffusion models excel at generating photorealistic images, but commonly struggle to render accurate spatial relationships described in text prompts. We identify two core issues underlying this common failure: 1) the ambiguous nature of spatial-related data in existing datasets, and 2) the inability of current text encoders to accurately interpret the spatial semantics of input descriptions. We address these issues with CoMPaSS, a versatile training framework that enhances spatial understanding of any T2I diffusion model. CoMPaSS solves the ambiguity of spatial-related data with the Spatial Constraints-Oriented Pairing (SCOP) data engine, which curates spatially-accurate training data through a set of principled spatial constraints. To better exploit the curated high-quality spatial priors, CoMPaSS further introduces a Token ENcoding ORdering (TENOR) module to allow better exploitation of high-quality spatial priors, effectively compensating for the shortcoming of text encoders. Extensive experiments on four popular open-weight T2I diffusion models covering both UNet- and MMDiT-based architectures demonstrate the effectiveness of CoMPaSS by setting new state-of-the-arts with substantial relative gains across well-known benchmarks on spatial relationships generation, including VISOR (+98%), T2I-CompBench Spatial (+67%), and GenEval Position (+131%). Code will be available at https://github.com/blurgyy/CoMPaSS.
High-quality Surface Reconstruction using Gaussian Surfels
Apr 30, 2024We propose a novel point-based representation, Gaussian surfels, to combine the advantages of the flexible optimization procedure in 3D Gaussian points and the surface alignment property of surfels. This is achieved by directly setting the z-scale of 3D Gaussian points to 0, effectively flattening the original 3D ellipsoid into a 2D ellipse. Such a design provides clear guidance to the optimizer. By treating the local z-axis as the normal direction, it greatly improves optimization stability and surface alignment. While the derivatives to the local z-axis computed from the covariance matrix are zero in this setting, we design a self-supervised normal-depth consistency loss to remedy this issue. Monocular normal priors and foreground masks are incorporated to enhance the quality of the reconstruction, mitigating issues related to highlights and background. We propose a volumetric cutting method to aggregate the information of Gaussian surfels so as to remove erroneous points in depth maps generated by alpha blending. Finally, we apply screened Poisson reconstruction method to the fused depth maps to extract the surface mesh. Experimental results show that our method demonstrates superior performance in surface reconstruction compared to state-of-the-art neural volume rendering and point-based rendering methods.
Deep3DPose: Realtime Reconstruction of Arbitrarily Posed Human Bodies from Single RGB Images
Jun 22, 2021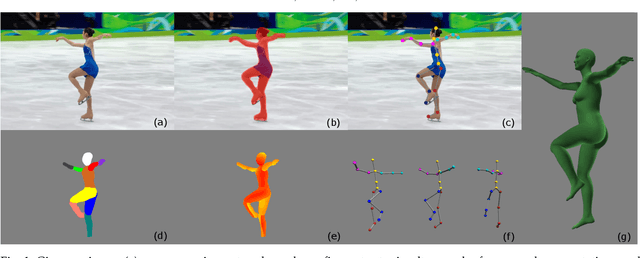

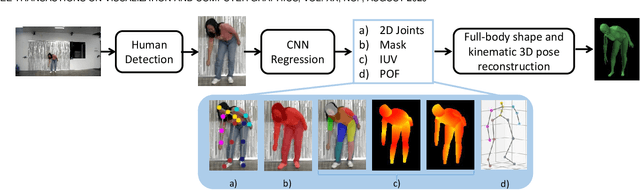
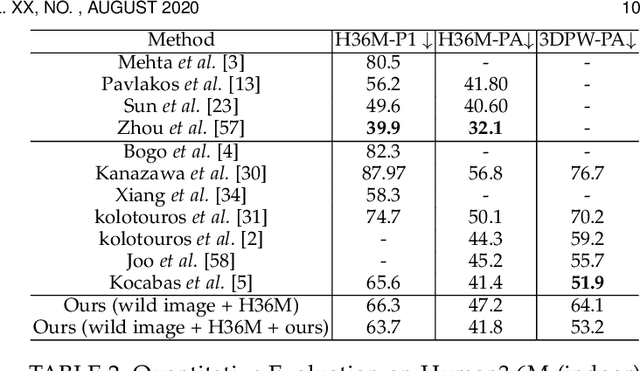
We introduce an approach that accurately reconstructs 3D human poses and detailed 3D full-body geometric models from single images in realtime. The key idea of our approach is a novel end-to-end multi-task deep learning framework that uses single images to predict five outputs simultaneously: foreground segmentation mask, 2D joints positions, semantic body partitions, 3D part orientations and uv coordinates (uv map). The multi-task network architecture not only generates more visual cues for reconstruction, but also makes each individual prediction more accurate. The CNN regressor is further combined with an optimization based algorithm for accurate kinematic pose reconstruction and full-body shape modeling. We show that the realtime reconstruction reaches accurate fitting that has not been seen before, especially for wild images. We demonstrate the results of our realtime 3D pose and human body reconstruction system on various challenging in-the-wild videos. We show the system advances the frontier of 3D human body and pose reconstruction from single images by quantitative evaluations and comparisons with state-of-the-art methods.
Bottom-up Pose Estimation of Multiple Person with Bounding Box Constraint
Jul 26, 2018



In this work, we propose a new method for multi-person pose estimation which combines the traditional bottom-up and the top-down methods. Specifically, we perform the network feed-forwarding in a bottom-up manner, and then parse the poses with bounding box constraints in a top-down manner. In contrast to the previous top-down methods, our method is robust to bounding box shift and tightness. We extract features from an original image by a residual network and train the network to learn both the confidence maps of joints and the connection relationships between joints. During testing, the predicted confidence maps, the connection relationships and the bounding boxes are used to parse the poses of all persons. The experimental results showed that our method learns more accurate human poses especially in challenging situations and gains better time performance, compared with the bottom-up and the top-down methods.