 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAU: Modeling Temporal Consistency Through Temporal Attentive U-Net for PPG Peak Detection
Mar 13, 2025Photoplethysmography (PPG) sensors have been widely used in consumer wearable devices to monitor heart rates (HR) and heart rate variability (HRV). Despite the prevalence, PPG signals can be contaminated by motion artifacts induced from daily activities. Existing approaches mainly use the amplitude information to perform PPG peak detection. However, these approaches cannot accurately identify peaks, since motion artifacts may bring random and significant amplitude variations. To improve the performance of PPG peak detection, the time information can be used. Specifically, heart rates exhibit temporal consistency that consecutive heartbeat intervals in a normal person can have limited variations. To leverage the temporal consistency, we propose the Temporal Attentive U-Net, i.e., TAU, to accurately detect peaks from PPG signals. In TAU, we design a time module that encodes temporal consistency in temporal embeddings. We integrate the amplitude information with temporal embeddings using the attention mechanism to estimate peak labels. Our experimental results show that TAU outperforms eleven baselines on heart rate estimation by more than 22.4%. Our TAU model achieves the best performance across various Signal-to-Noise Ratio (SNR) levels. Moreover, we achieve Pearson correlation coefficients higher than 0.9 (p < 0.01) on estimating HRV features from low-noise-level PPG signals.
Deep3DPose: Realtime Reconstruction of Arbitrarily Posed Human Bodies from Single RGB Images
Jun 22, 2021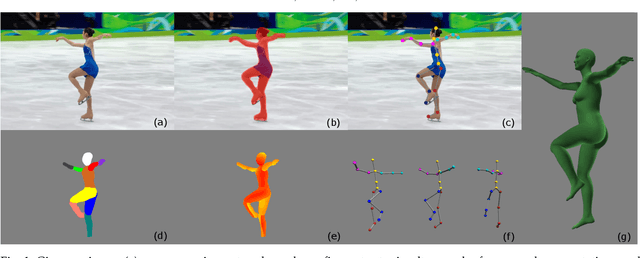

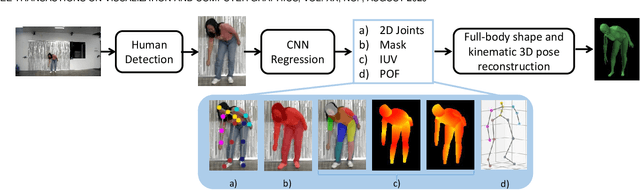
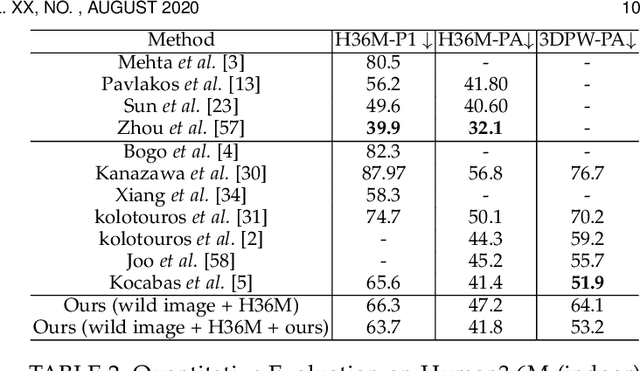
We introduce an approach that accurately reconstructs 3D human poses and detailed 3D full-body geometric models from single images in realtime. The key idea of our approach is a novel end-to-end multi-task deep learning framework that uses single images to predict five outputs simultaneously: foreground segmentation mask, 2D joints positions, semantic body partitions, 3D part orientations and uv coordinates (uv map). The multi-task network architecture not only generates more visual cues for reconstruction, but also makes each individual prediction more accurate. The CNN regressor is further combined with an optimization based algorithm for accurate kinematic pose reconstruction and full-body shape modeling. We show that the realtime reconstruction reaches accurate fitting that has not been seen before, especially for wild images. We demonstrate the results of our realtime 3D pose and human body reconstruction system on various challenging in-the-wild videos. We show the system advances the frontier of 3D human body and pose reconstruction from single images by quantitative evaluations and comparisons with state-of-the-art methods.
Deep Deformation Detail Synthesis for Thin Shell Models
Feb 23, 2021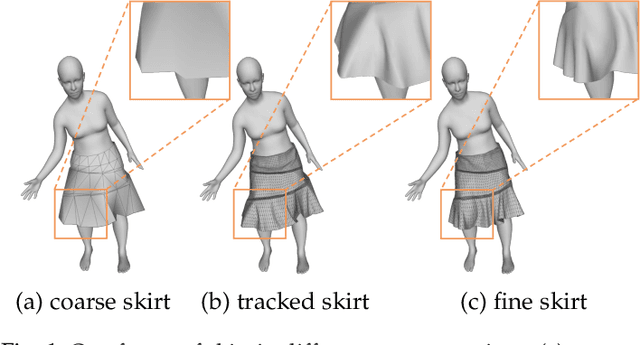
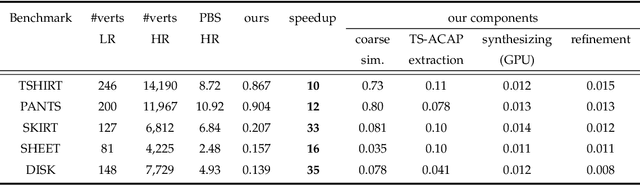
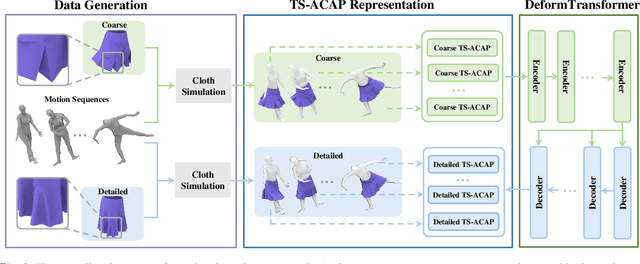
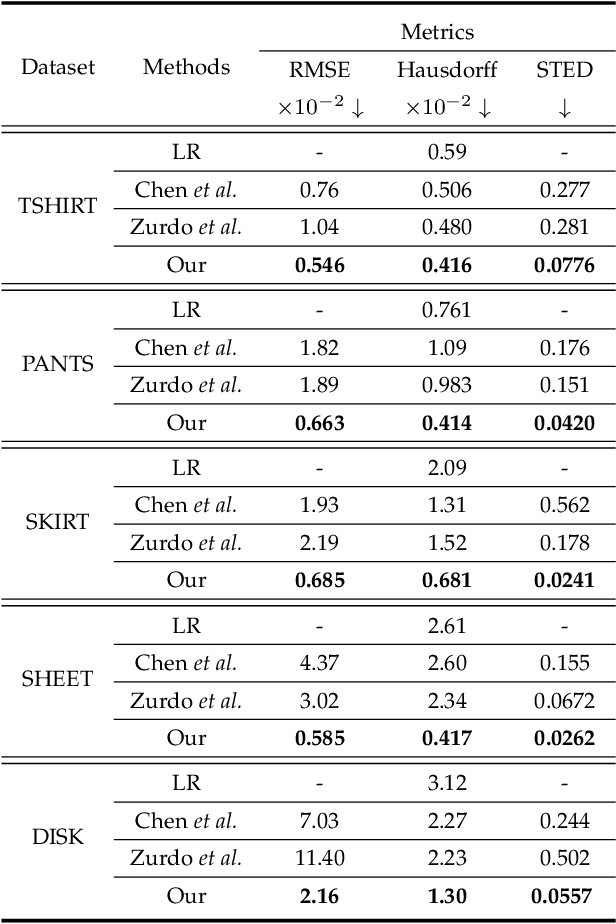
In physics-based cloth animation, rich folds and detailed wrinkles are achieved at the cost of expensive computational resources and huge labor tuning. Data-driven techniques make efforts to reduce the computation significantly by a database. One type of methods relies on human poses to synthesize fitted garments which cannot be applied to general cloth. Another type of methods adds details to the coarse meshes without such restrictions. However, existing works usually utilize coordinate-based representations which cannot cope with large-scale deformation, and requires dense vertex correspondences between coarse and fine meshes. Moreover, as such methods only add details, they require coarse meshes to be close to fine meshes, which can be either impossible, or require unrealistic constraints when generating fine meshes. To address these challenges, we develop a temporally and spatially as-consistent-as-possible deformation representation (named TS-ACAP) and a DeformTransformer network to learn the mapping from low-resolution meshes to detailed ones. This TS-ACAP representation is designed to ensure both spatial and temporal consistency for sequential large-scale deformations from cloth animations. With this representation, our DeformTransformer network first utilizes two mesh-based encoders to extract the coarse and fine features, respectively. To transduct the coarse features to the fine ones, we leverage the Transformer network that consists of frame-level attention mechanisms to ensure temporal coherence of the prediction. Experimental results show that our method is able to produce reliable and realistic animations in various datasets at high frame rates: 10 ~ 35 times faster than physics-based simulation, with superior detail synthesis abilities than existing methods.
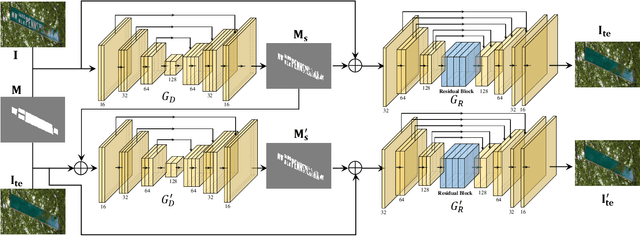
Scene text removal via cascaded text stroke detection and erasing
Nov 19, 2020
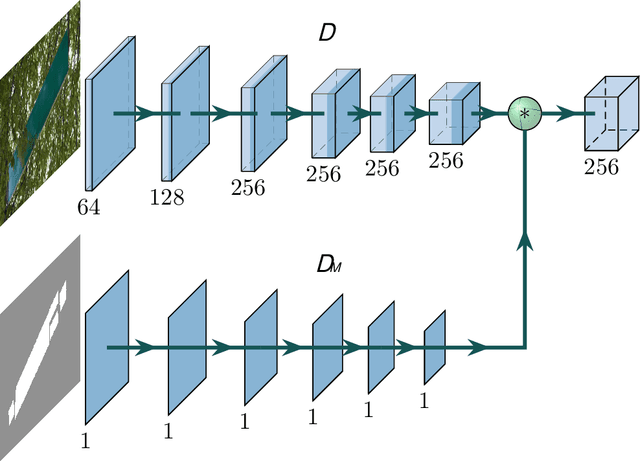

Recent learning-based approaches show promising performance improvement for scene text removal task. However, these methods usually leave some remnants of text and obtain visually unpleasant results. In this work, we propose a novel "end-to-end" framework based on accurate text stroke detection. Specifically, we decouple the text removal problem into text stroke detection and stroke removal. We design a text stroke detection network and a text removal generation network to solve these two sub-problems separately. Then, we combine these two networks as a processing unit, and cascade this unit to obtain the final model for text removal. Experimental results demonstrate that the proposed method significantly outperforms the state-of-the-art approaches for locating and erasing scene text. Since current publicly available datasets are all synthetic and cannot properly measure the performance of different methods, we therefore construct a new real-world dataset, which will be released to facilitate the relevant research.