 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Deformation Detail Synthesis for Thin Shell Models
Paper and Code
Feb 23, 2021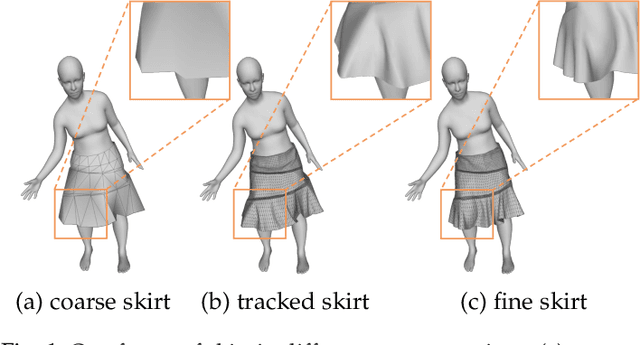
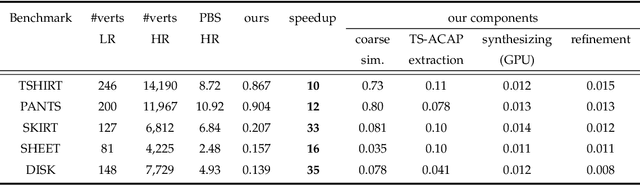
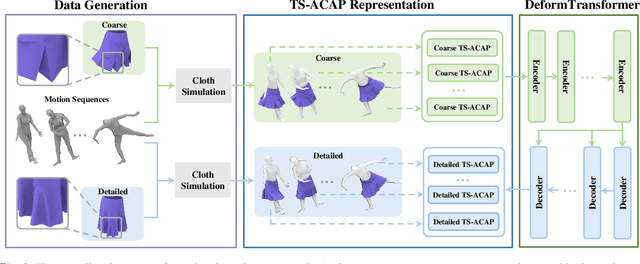
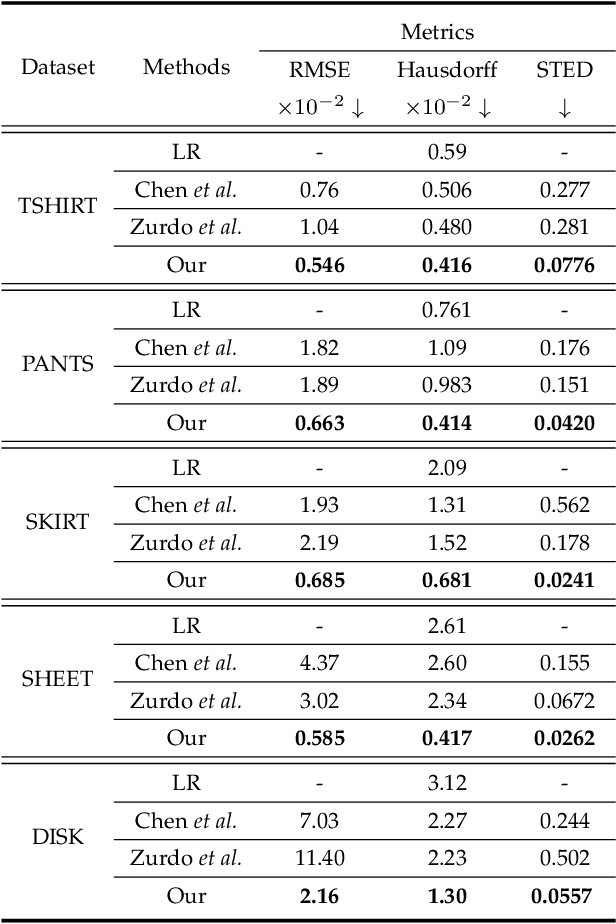
In physics-based cloth animation, rich folds and detailed wrinkles are achieved at the cost of expensive computational resources and huge labor tuning. Data-driven techniques make efforts to reduce the computation significantly by a database. One type of methods relies on human poses to synthesize fitted garments which cannot be applied to general cloth. Another type of methods adds details to the coarse meshes without such restrictions. However, existing works usually utilize coordinate-based representations which cannot cope with large-scale deformation, and requires dense vertex correspondences between coarse and fine meshes. Moreover, as such methods only add details, they require coarse meshes to be close to fine meshes, which can be either impossible, or require unrealistic constraints when generating fine meshes. To address these challenges, we develop a temporally and spatially as-consistent-as-possible deformation representation (named TS-ACAP) and a DeformTransformer network to learn the mapping from low-resolution meshes to detailed ones. This TS-ACAP representation is designed to ensure both spatial and temporal consistency for sequential large-scale deformations from cloth animations. With this representation, our DeformTransformer network first utilizes two mesh-based encoders to extract the coarse and fine features, respectively. To transduct the coarse features to the fine ones, we leverage the Transformer network that consists of frame-level attention mechanisms to ensure temporal coherence of the prediction. Experimental results show that our method is able to produce reliable and realistic animations in various datasets at high frame rates: 10 ~ 35 times faster than physics-based simulation, with superior detail synthesis abilities than existing methods.