 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep3DPose: Realtime Reconstruction of Arbitrarily Posed Human Bodies from Single RGB Images
Jun 22, 2021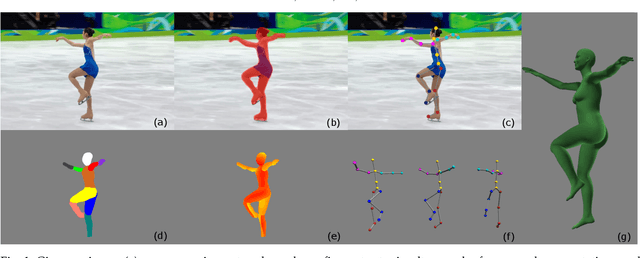

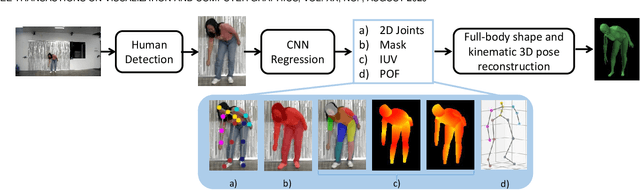
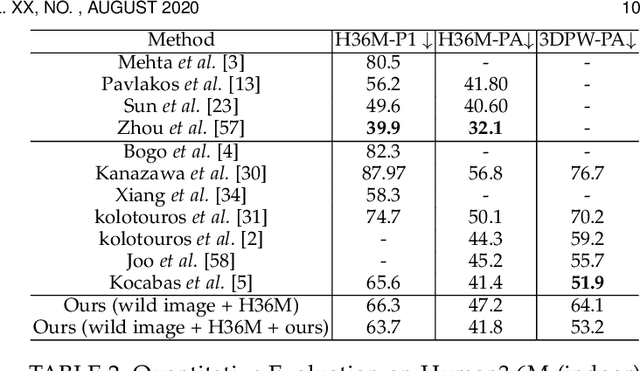
We introduce an approach that accurately reconstructs 3D human poses and detailed 3D full-body geometric models from single images in realtime. The key idea of our approach is a novel end-to-end multi-task deep learning framework that uses single images to predict five outputs simultaneously: foreground segmentation mask, 2D joints positions, semantic body partitions, 3D part orientations and uv coordinates (uv map). The multi-task network architecture not only generates more visual cues for reconstruction, but also makes each individual prediction more accurate. The CNN regressor is further combined with an optimization based algorithm for accurate kinematic pose reconstruction and full-body shape modeling. We show that the realtime reconstruction reaches accurate fitting that has not been seen before, especially for wild images. We demonstrate the results of our realtime 3D pose and human body reconstruction system on various challenging in-the-wild videos. We show the system advances the frontier of 3D human body and pose reconstruction from single images by quantitative evaluations and comparisons with state-of-the-art methods.
Bottom-up Pose Estimation of Multiple Person with Bounding Box Constraint
Jul 26, 2018



In this work, we propose a new method for multi-person pose estimation which combines the traditional bottom-up and the top-down methods. Specifically, we perform the network feed-forwarding in a bottom-up manner, and then parse the poses with bounding box constraints in a top-down manner. In contrast to the previous top-down methods, our method is robust to bounding box shift and tightness. We extract features from an original image by a residual network and train the network to learn both the confidence maps of joints and the connection relationships between joints. During testing, the predicted confidence maps, the connection relationships and the bounding boxes are used to parse the poses of all persons. The experimental results showed that our method learns more accurate human poses especially in challenging situations and gains better time performance, compared with the bottom-up and the top-down methods.