 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2M-HiFiGPT: Generating High Quality Human Motion from Textual Descriptions with Residual Discrete Representations
Dec 24, 2023In this study, we introduce T2M-HiFiGPT, a novel conditional generative framework for synthesizing human motion from textual descriptions. This framework is underpinned by a Residual Vector Quantized Variational AutoEncoder (RVQ-VAE) and a double-tier Generative Pretrained Transformer (GPT) architecture. We demonstrate that our CNN-based RVQ-VAE is capable of producing highly accurate 2D temporal-residual discrete motion representations. Our proposed double-tier GPT structure comprises a temporal GPT and a residual GPT. The temporal GPT efficiently condenses information from previous frames and textual descriptions into a 1D context vector. This vector then serves as a context prompt for the residual GPT, which generates the final residual discrete indices. These indices are subsequently transformed back into motion data by the RVQ-VAE decoder. To mitigate the exposure bias issue, we employ straightforward code corruption techniques for RVQ and a conditional dropout strategy, resulting in enhanced synthesis performance. Remarkably, T2M-HiFiGPT not only simplifies the generative process but also surpasses existing methods in both performance and parameter efficacy, including the latest diffusion-based and GPT-based models. On the HumanML3D and KIT-ML datasets, our framework achieves exceptional results across nearly all primary metrics. We further validate the efficacy of our framework through comprehensive ablation studies on the HumanML3D dataset, examining the contribution of each component. Our findings reveal that RVQ-VAE is more adept at capturing precise 3D human motion with comparable computational demand compared to its VQ-VAE counterparts. As a result, T2M-HiFiGPT enables the generation of human motion with significantly increased accuracy, outperforming recent state-of-the-art approaches such as T2M-GPT and Att-T2M.
HandMIM: Pose-Aware Self-Supervised Learning for 3D Hand Mesh Estimation
Jul 29, 2023With an enormous number of hand images generated over time, unleashing pose knowledge from unlabeled images for supervised hand mesh estimation is an emerging yet challenging topic. To alleviate this issue, semi-supervised and self-supervised approaches have been proposed, but they are limited by the reliance on detection models or conventional ResNet backbones. In this paper, inspired by the rapid progress of Masked Image Modeling (MIM) in visual classification tasks, we propose a novel self-supervised pre-training strategy for regressing 3D hand mesh parameters. Our approach involves a unified and multi-granularity strategy that includes a pseudo keypoint alignment module in the teacher-student framework for learning pose-aware semantic class tokens. For patch tokens with detailed locality, we adopt a self-distillation manner between teacher and student network based on MIM pre-training. To better fit low-level regression tasks, we incorporate pixel reconstruction tasks for multi-level representation learning. Additionally, we design a strong pose estimation baseline using a simple vanilla vision Transformer (ViT) as the backbone and attach a PyMAF head after tokens for regression. Extensive experiments demonstrate that our proposed approach, named HandMIM, achieves strong performance on various hand mesh estimation tasks. Notably, HandMIM outperforms specially optimized architectures, achieving 6.29mm and 8.00mm PAVPE (Vertex-Point-Error) on challenging FreiHAND and HO3Dv2 test sets, respectively, establishing new state-of-the-art records on 3D hand mesh estimation.
MeMaHand: Exploiting Mesh-Mano Interaction for Single Image Two-Hand Reconstruction
Apr 17, 2023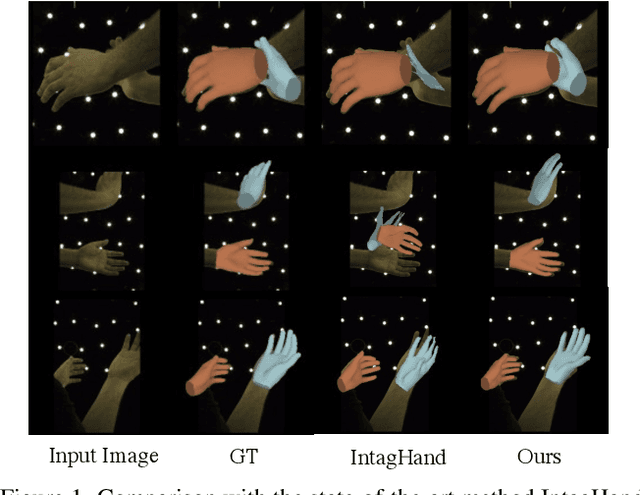

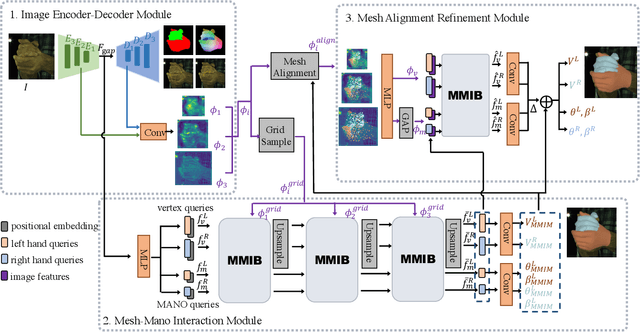

Existing methods proposed for hand reconstruction tasks usually parameterize a generic 3D hand model or predict hand mesh positions directly. The parametric representations consisting of hand shapes and rotational poses are more stable, while the non-parametric methods can predict more accurate mesh positions. In this paper, we propose to reconstruct meshes and estimate MANO parameters of two hands from a single RGB image simultaneously to utilize the merits of two kinds of hand representations. To fulfill this target, we propose novel Mesh-Mano interaction blocks (MMIBs), which take mesh vertices positions and MANO parameters as two kinds of query tokens. MMIB consists of one graph residual block to aggregate local information and two transformer encoders to model long-range dependencies. The transformer encoders are equipped with different asymmetric attention masks to model the intra-hand and inter-hand attention, respectively. Moreover, we introduce the mesh alignment refinement module to further enhance the mesh-image alignment. Extensive experiments on the InterHand2.6M benchmark demonstrate promising results over the state-of-the-art hand reconstruction methods.
Deep3DPose: Realtime Reconstruction of Arbitrarily Posed Human Bodies from Single RGB Images
Jun 22, 2021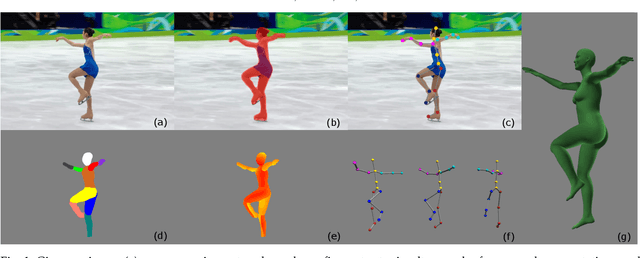

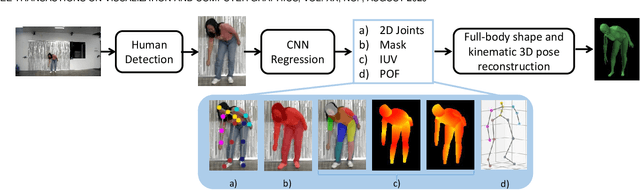
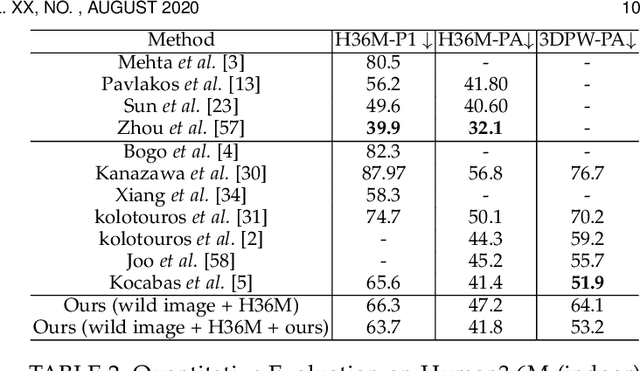
We introduce an approach that accurately reconstructs 3D human poses and detailed 3D full-body geometric models from single images in realtime. The key idea of our approach is a novel end-to-end multi-task deep learning framework that uses single images to predict five outputs simultaneously: foreground segmentation mask, 2D joints positions, semantic body partitions, 3D part orientations and uv coordinates (uv map). The multi-task network architecture not only generates more visual cues for reconstruction, but also makes each individual prediction more accurate. The CNN regressor is further combined with an optimization based algorithm for accurate kinematic pose reconstruction and full-body shape modeling. We show that the realtime reconstruction reaches accurate fitting that has not been seen before, especially for wild images. We demonstrate the results of our realtime 3D pose and human body reconstruction system on various challenging in-the-wild videos. We show the system advances the frontier of 3D human body and pose reconstruction from single images by quantitative evaluations and comparisons with state-of-the-art methods.
Improve GAN-based Neural Vocoder using Pointwise Relativistic LeastSquare GAN
Mar 29, 2021
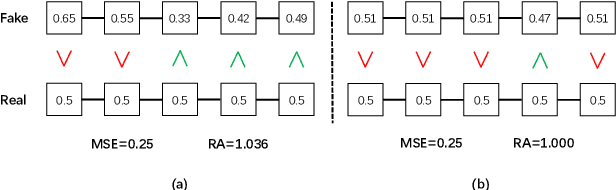
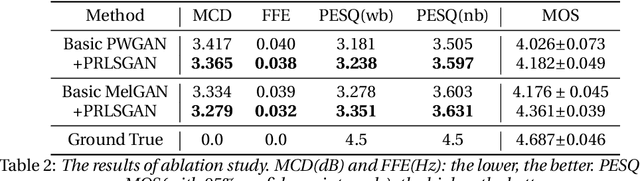
GAN-based neural vocoders, such as Parallel WaveGAN and MelGAN have attracted great interest due to their lightweight and parallel structures, enabling them to generate high fidelity waveform in a real-time manner. In this paper, inspired by Relativistic GAN, we introduce a novel variant of the LSGAN framework under the context of waveform synthesis, named Pointwise Relativistic LSGAN (PRLSGAN). In this approach, we take the truism score distribution into consideration and combine the original MSE loss with the proposed pointwise relative discrepancy loss to increase the difficulty of the generator to fool the discriminator, leading to improved generation quality. Moreover, PRLSGAN is a general-purposed framework that can be combined with any GAN-based neural vocoder to enhance its generation quality. Experiments have shown a consistent performance boost based on Parallel WaveGAN and MelGAN, demonstrating the effectiveness and strong generalization ability of our proposed PRLSGAN neural vocoders.
Polyphone Disambiguition in Mandarin Chinese with Semi-Supervised Learning
Feb 01, 2021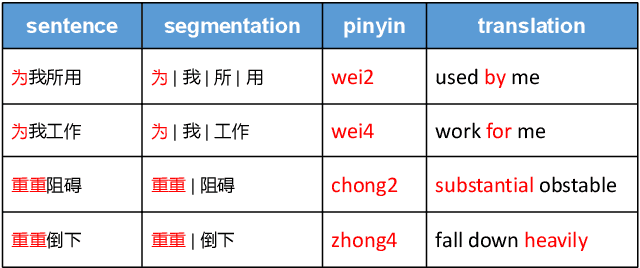

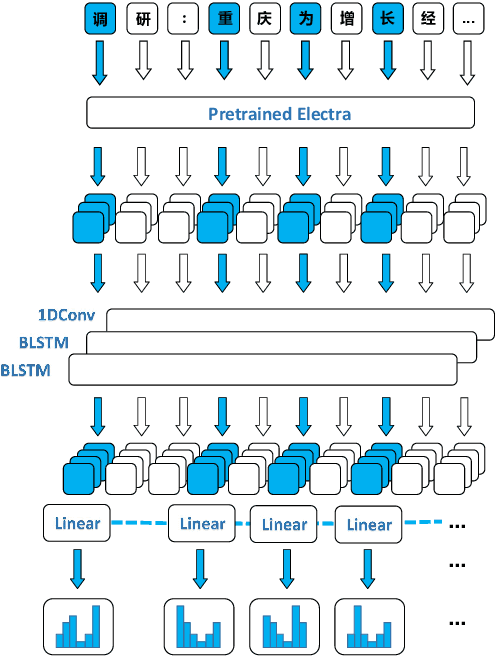
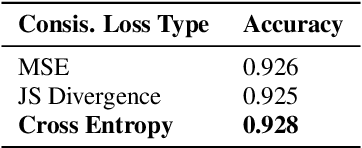
The majority of Chinese characters are monophonic, i.e.their pronunciations are unique and thus can be induced easily using a check table. As for their counterparts, polyphonic characters have more than one pronunciation. To perform linguistic computation tasks related to spoken Mandarin Chinese, the correct pronunciation for each polyphone must be identified among several candidates according to its context. This process is called Polyphone Disambiguation, a key procedure in the Grapheme-to-phoneme (G2P) conversion step of a Chinese text-to-speech (TTS) system. The problem is well explored with both knowledge-based and learning-based approaches, yet it remains challenging due to the lack of publicly available datasets and complex language phenomenon concerned polyphone. In this paper, we propose a novel semi-supervised learning (SSL) framework for Mandarin Chinese polyphone disambiguation that can potentially leverage unlimited unlabeled text data. We explore the effect of various proxy labeling strategies including entropy-thresholding and lexicon-based labeling. As for the architecture, a pre-trained model of Electra is combined with Convolution BLSTM layers to fine-tune on our task. Qualitative and quantitative experiments demonstrate that our method achieves state-of-the-art performance in Mandarin Chinese polyphone disambiguation. In addition, we publish a novel dataset specifically for the polyphone disambiguation task to promote further researches.
Music2Dance: DanceNet for Music-driven Dance Generation
Mar 10, 2020
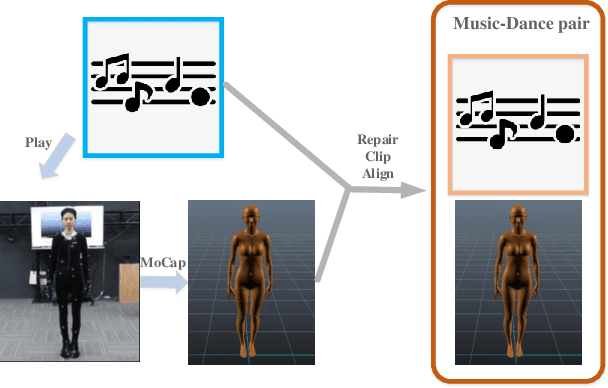

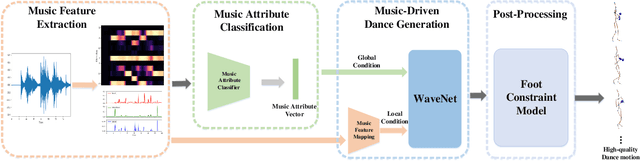
Synthesize human motions from music, i.e., music to dance, is appealing and attracts lots of research interests in recent years. It is challenging due to not only the requirement of realistic and complex human motions for dance, but more importantly, the synthesized motions should be consistent with the style, rhythm and melody of the music. In this paper, we propose a novel autoregressive generative model, DanceNet, to take the style, rhythm and melody of music as the control signals to generate 3D dance motions with high realism and diversity. To boost the performance of our proposed model, we capture several synchronized music-dance pairs by professional dancers, and build a high-quality music-dance pair dataset. Experiments have demonstrated that the proposed method can achieve the state-of-the-art results.