 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyphone Disambiguition in Mandarin Chinese with Semi-Supervised Learning
Paper and Code
Feb 01, 2021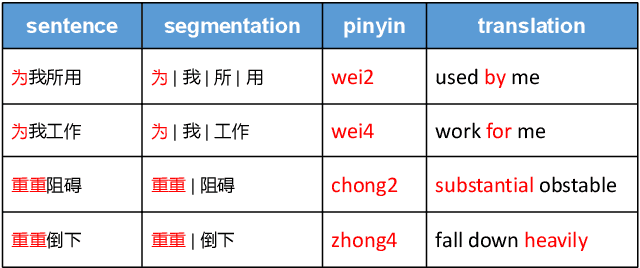

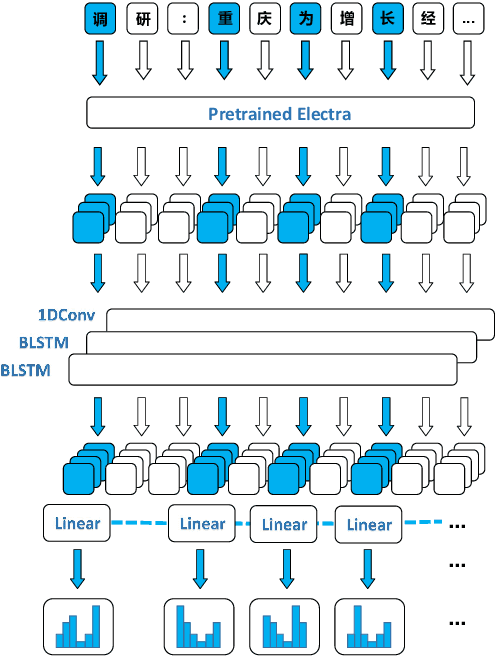
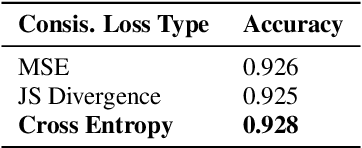
The majority of Chinese characters are monophonic, i.e.their pronunciations are unique and thus can be induced easily using a check table. As for their counterparts, polyphonic characters have more than one pronunciation. To perform linguistic computation tasks related to spoken Mandarin Chinese, the correct pronunciation for each polyphone must be identified among several candidates according to its context. This process is called Polyphone Disambiguation, a key procedure in the Grapheme-to-phoneme (G2P) conversion step of a Chinese text-to-speech (TTS) system. The problem is well explored with both knowledge-based and learning-based approaches, yet it remains challenging due to the lack of publicly available datasets and complex language phenomenon concerned polyphone. In this paper, we propose a novel semi-supervised learning (SSL) framework for Mandarin Chinese polyphone disambiguation that can potentially leverage unlimited unlabeled text data. We explore the effect of various proxy labeling strategies including entropy-thresholding and lexicon-based labeling. As for the architecture, a pre-trained model of Electra is combined with Convolution BLSTM layers to fine-tune on our task. Qualitative and quantitative experiments demonstrate that our method achieves state-of-the-art performance in Mandarin Chinese polyphone disambiguation. In addition, we publish a novel dataset specifically for the polyphone disambiguation task to promote further researches.