 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Speech Portraits: Real-Time Photorealistic Talking-Head Animation
Sep 24, 2021
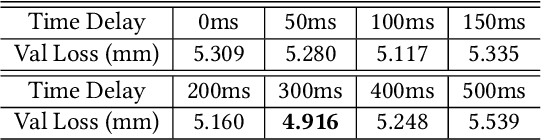
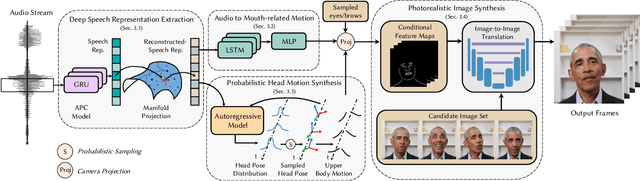
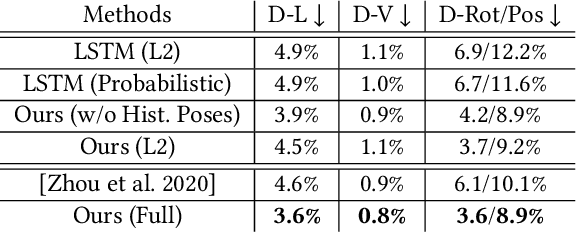
To the best of our knowledge, we first present a live system that generates personalized photorealistic talking-head animation only driven by audio signals at over 30 fps. Our system contains three stages. The first stage is a deep neural network that extracts deep audio features along with a manifold projection to project the features to the target person's speech space. In the second stage, we learn facial dynamics and motions from the projected audio features. The predicted motions include head poses and upper body motions, where the former is generated by an autoregressive probabilistic model which models the head pose distribution of the target person. Upper body motions are deduced from head poses. In the final stage, we generate conditional feature maps from previous predictions and send them with a candidate image set to an image-to-image translation network to synthesize photorealistic renderings. Our method generalizes well to wild audio and successfully synthesizes high-fidelity personalized facial details, e.g., wrinkles, teeth. Our method also allows explicit control of head poses. Extensive qualitative and quantitative evaluations, along with user studies, demonstrate the superiority of our method over state-of-the-art techniques.
Deep3DPose: Realtime Reconstruction of Arbitrarily Posed Human Bodies from Single RGB Images
Jun 22, 2021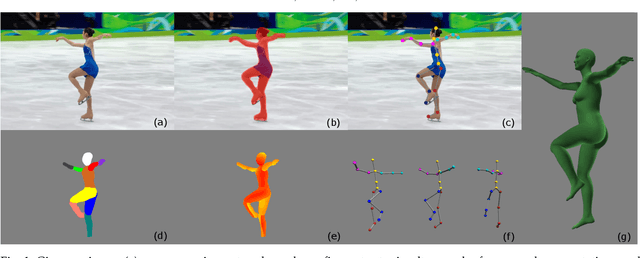

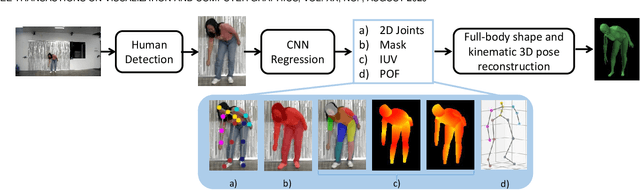
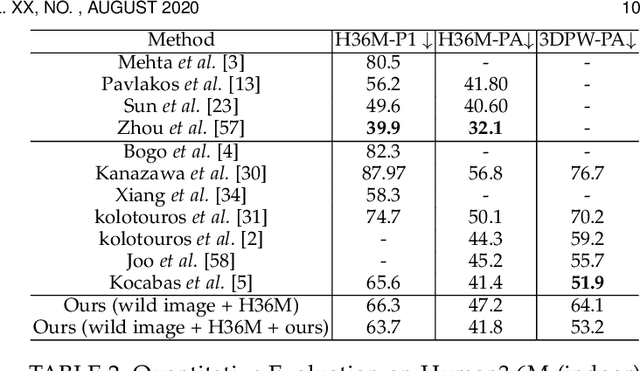
We introduce an approach that accurately reconstructs 3D human poses and detailed 3D full-body geometric models from single images in realtime. The key idea of our approach is a novel end-to-end multi-task deep learning framework that uses single images to predict five outputs simultaneously: foreground segmentation mask, 2D joints positions, semantic body partitions, 3D part orientations and uv coordinates (uv map). The multi-task network architecture not only generates more visual cues for reconstruction, but also makes each individual prediction more accurate. The CNN regressor is further combined with an optimization based algorithm for accurate kinematic pose reconstruction and full-body shape modeling. We show that the realtime reconstruction reaches accurate fitting that has not been seen before, especially for wild images. We demonstrate the results of our realtime 3D pose and human body reconstruction system on various challenging in-the-wild videos. We show the system advances the frontier of 3D human body and pose reconstruction from single images by quantitative evaluations and comparisons with state-of-the-art methods.
Music2Dance: DanceNet for Music-driven Dance Generation
Mar 10, 2020
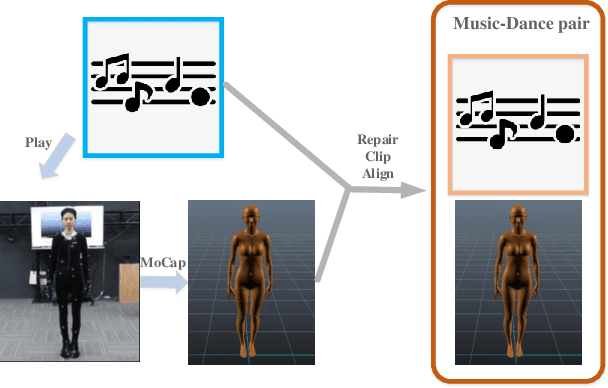

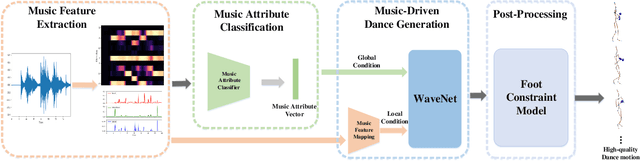
Synthesize human motions from music, i.e., music to dance, is appealing and attracts lots of research interests in recent years. It is challenging due to not only the requirement of realistic and complex human motions for dance, but more importantly, the synthesized motions should be consistent with the style, rhythm and melody of the music. In this paper, we propose a novel autoregressive generative model, DanceNet, to take the style, rhythm and melody of music as the control signals to generate 3D dance motions with high realism and diversity. To boost the performance of our proposed model, we capture several synchronized music-dance pairs by professional dancers, and build a high-quality music-dance pair dataset. Experiments have demonstrated that the proposed method can achieve the state-of-the-art results.