 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentar-Fin-OCR
Mar 11, 2026In this paper, we propose Agentar-Fin-OCR, a document parsing system tailored to financial-domain documents, transforming ultra-long financial PDFs into semantically consistent, highly accurate, structured outputs with auditing-grade provenance. To address finance-specific challenges such as complex layouts, cross-page structural discontinuities, and cell-level referencing capability, Agentar-Fin-OCR combines (1) a Cross-page Contents Consolidation algorithm to restore continuity across pages and a Document-level Heading Hierarchy Reconstruction (DHR) module to build a globally consistent Table of Contents (TOC) tree for structure-aware retrieval, and (2) a difficulty-adaptive curriculum learning training strategy for table parsing, together with a CellBBoxRegressor module that uses structural anchor tokens to localize table cells from decoder hidden states without external detectors. Experiments demonstrate that our model shows high performance on the table parsing metrics of OmniDocBench. To enable realistic evaluation in the financial vertical, we further introduce FinDocBench, a benchmark that includes six financial document categories with expert-verified annotations and evaluation metrics including Table of Contents edit-distance-based similarity (TocEDS), cross-page concatenated TEDS, and Table Cell Intersection over Union (C-IoU). We evaluate a wide range of state-of-the-art models on FinDocBench to assess their capabilities and remaining limitations on financial documents. Overall, Agentar-Fin-OCR and FinDocBench provide a practical foundation for reliable downstream financial document applications.
OMGSR: You Only Need One Mid-timestep Guidance for Real-World Image Super-Resolution
Aug 11, 2025Denoising Diffusion Probabilistic Models (DDPM) and Flow Matching (FM) generative models show promising potential for one-step Real-World Image Super-Resolution (Real-ISR). Recent one-step Real-ISR models typically inject a Low-Quality (LQ) image latent distribution at the initial timestep. However, a fundamental gap exists between the LQ image latent distribution and the Gaussian noisy latent distribution, limiting the effective utilization of generative priors. We observe that the noisy latent distribution at DDPM/FM mid-timesteps aligns more closely with the LQ image latent distribution. Based on this insight, we present One Mid-timestep Guidance Real-ISR (OMGSR), a universal framework applicable to DDPM/FM-based generative models. OMGSR injects the LQ image latent distribution at a pre-computed mid-timestep, incorporating the proposed Latent Distribution Refinement loss to alleviate the latent distribution gap. We also design the Overlap-Chunked LPIPS/GAN loss to eliminate checkerboard artifacts in image generation. Within this framework, we instantiate OMGSR for DDPM/FM-based generative models with two variants: OMGSR-S (SD-Turbo) and OMGSR-F (FLUX.1-dev). Experimental results demonstrate that OMGSR-S/F achieves balanced/excellent performance across quantitative and qualitative metrics at 512-resolution. Notably, OMGSR-F establishes overwhelming dominance in all reference metrics. We further train a 1k-resolution OMGSR-F to match the default resolution of FLUX.1-dev, which yields excellent results, especially in the details of the image generation. We also generate 2k-resolution images by the 1k-resolution OMGSR-F using our two-stage Tiled VAE & Diffusion.
CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models
Dec 17, 2024



Text-to-image diffusion models excel at generating photorealistic images, but commonly struggle to render accurate spatial relationships described in text prompts. We identify two core issues underlying this common failure: 1) the ambiguous nature of spatial-related data in existing datasets, and 2) the inability of current text encoders to accurately interpret the spatial semantics of input descriptions. We address these issues with CoMPaSS, a versatile training framework that enhances spatial understanding of any T2I diffusion model. CoMPaSS solves the ambiguity of spatial-related data with the Spatial Constraints-Oriented Pairing (SCOP) data engine, which curates spatially-accurate training data through a set of principled spatial constraints. To better exploit the curated high-quality spatial priors, CoMPaSS further introduces a Token ENcoding ORdering (TENOR) module to allow better exploitation of high-quality spatial priors, effectively compensating for the shortcoming of text encoders. Extensive experiments on four popular open-weight T2I diffusion models covering both UNet- and MMDiT-based architectures demonstrate the effectiveness of CoMPaSS by setting new state-of-the-arts with substantial relative gains across well-known benchmarks on spatial relationships generation, including VISOR (+98%), T2I-CompBench Spatial (+67%), and GenEval Position (+131%). Code will be available at https://github.com/blurgyy/CoMPaSS.
AuthFace: Towards Authentic Blind Face Restoration with Face-oriented Generative Diffusion Prior
Oct 13, 2024
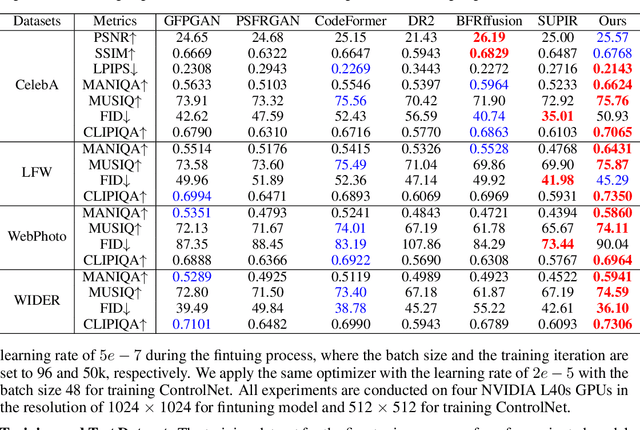


Blind face restoration (BFR) is a fundamental and challenging problem in computer vision. To faithfully restore high-quality (HQ) photos from poor-quality ones, recent research endeavors predominantly rely on facial image priors from the powerful pretrained text-to-image (T2I) diffusion models. However, such priors often lead to the incorrect generation of non-facial features and insufficient facial details, thus rendering them less practical for real-world applications. In this paper, we propose a novel framework, namely AuthFace that achieves highly authentic face restoration results by exploring a face-oriented generative diffusion prior. To learn such a prior, we first collect a dataset of 1.5K high-quality images, with resolutions exceeding 8K, captured by professional photographers. Based on the dataset, we then introduce a novel face-oriented restoration-tuning pipeline that fine-tunes a pretrained T2I model. Identifying key criteria of quality-first and photography-guided annotation, we involve the retouching and reviewing process under the guidance of photographers for high-quality images that show rich facial features. The photography-guided annotation system fully explores the potential of these high-quality photographic images. In this way, the potent natural image priors from pretrained T2I diffusion models can be subtly harnessed, specifically enhancing their capability in facial detail restoration. Moreover, to minimize artifacts in critical facial areas, such as eyes and mouth, we propose a time-aware latent facial feature loss to learn the authentic face restoration process. Extensive experiments on the synthetic and real-world BFR datasets demonstrate the superiority of our approach.
Robust Human Matting via Semantic Guidance
Oct 11, 2022
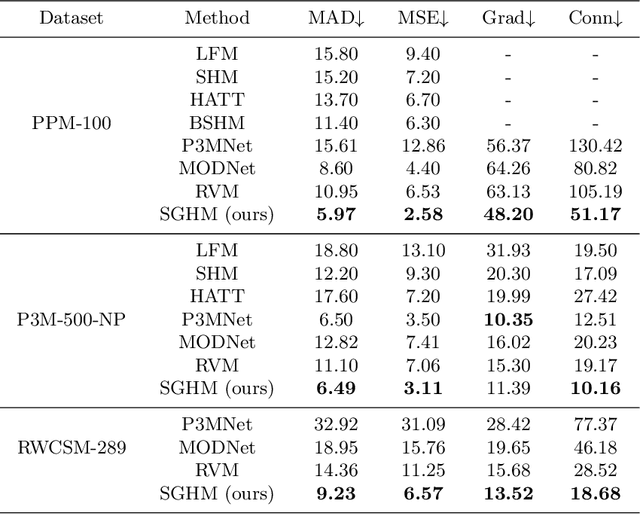
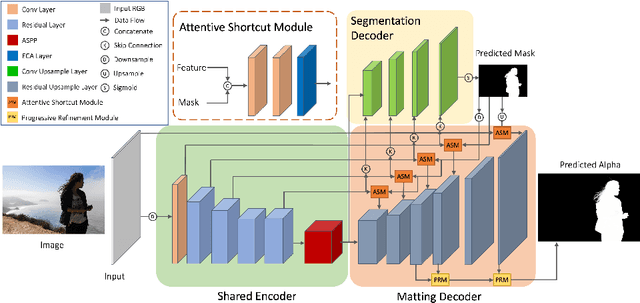
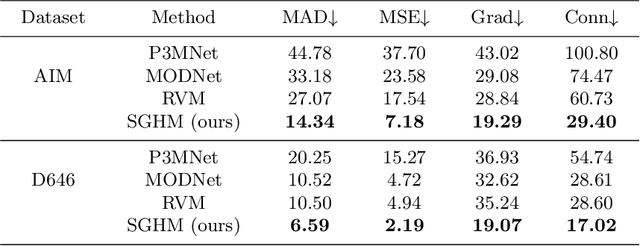
Automatic human matting is highly desired for many real applications. We investigate recent human matting methods and show that common bad cases happen when semantic human segmentation fails. This indicates that semantic understanding is crucial for robust human matting. From this, we develop a fast yet accurate human matting framework, named Semantic Guided Human Matting (SGHM). It builds on a semantic human segmentation network and introduces a light-weight matting module with only marginal computational cost. Unlike previous works, our framework is data efficient, which requires a small amount of matting ground-truth to learn to estimate high quality object mattes. Our experiments show that trained with merely 200 matting images, our method can generalize well to real-world datasets, and outperform recent methods on multiple benchmarks, while remaining efficient. Considering the unbearable labeling cost of matting data and widely available segmentation data, our method becomes a practical and effective solution for the task of human matting. Source code is available at https://github.com/cxgincsu/SemanticGuidedHumanMatting.