 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAP-SR: RestorAtion Prior Enhancement in Diffusion Models for Realistic Image Super-Resolution
Dec 10, 2024



Benefiting from their powerful generative capabilities, pretrained diffusion models have garnered significant attention for real-world image super-resolution (Real-SR). Existing diffusion-based SR approaches typically utilize semantic information from degraded images and restoration prompts to activate prior for producing realistic high-resolution images. However, general-purpose pretrained diffusion models, not designed for restoration tasks, often have suboptimal prior, and manually defined prompts may fail to fully exploit the generated potential. To address these limitations, we introduce RAP-SR, a novel restoration prior enhancement approach in pretrained diffusion models for Real-SR. First, we develop the High-Fidelity Aesthetic Image Dataset (HFAID), curated through a Quality-Driven Aesthetic Image Selection Pipeline (QDAISP). Our dataset not only surpasses existing ones in fidelity but also excels in aesthetic quality. Second, we propose the Restoration Priors Enhancement Framework, which includes Restoration Priors Refinement (RPR) and Restoration-Oriented Prompt Optimization (ROPO) modules. RPR refines the restoration prior using the HFAID, while ROPO optimizes the unique restoration identifier, improving the quality of the resulting images. RAP-SR effectively bridges the gap between general-purpose models and the demands of Real-SR by enhancing restoration prior. Leveraging the plug-and-play nature of RAP-SR, our approach can be seamlessly integrated into existing diffusion-based SR methods, boosting their performance. Extensive experiments demonstrate its broad applicability and state-of-the-art results. Codes and datasets will be available upon acceptance.
Hero-SR: One-Step Diffusion for Super-Resolution with Human Perception Priors
Dec 10, 2024
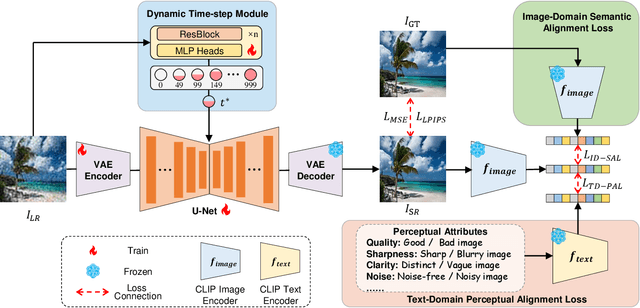
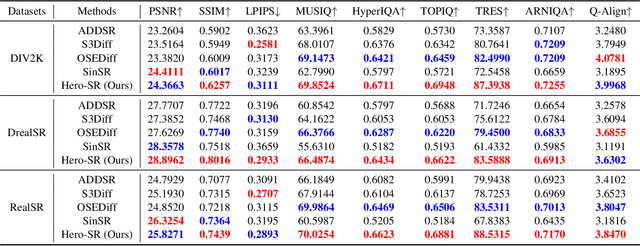
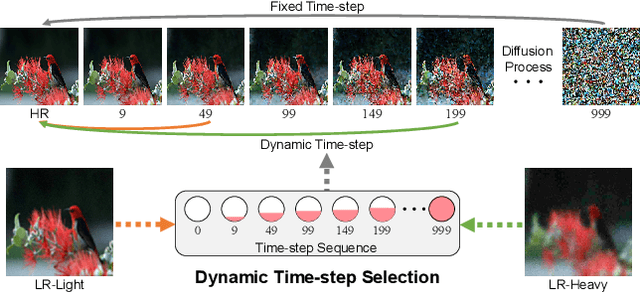
Owing to the robust priors of diffusion models, recent approaches have shown promise in addressing real-world super-resolution (Real-SR). However, achieving semantic consistency and perceptual naturalness to meet human perception demands remains difficult, especially under conditions of heavy degradation and varied input complexities. To tackle this, we propose Hero-SR, a one-step diffusion-based SR framework explicitly designed with human perception priors. Hero-SR consists of two novel modules: the Dynamic Time-Step Module (DTSM), which adaptively selects optimal diffusion steps for flexibly meeting human perceptual standards, and the Open-World Multi-modality Supervision (OWMS), which integrates guidance from both image and text domains through CLIP to improve semantic consistency and perceptual naturalness. Through these modules, Hero-SR generates high-resolution images that not only preserve intricate details but also reflect human perceptual preferences. Extensive experiments validate that Hero-SR achieves state-of-the-art performance in Real-SR. The code will be publicly available upon paper acceptance.