 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMLET: A Hierarchical Multimodal Attention-based Human Activity Recognition Algorithm
Paper and Code
Aug 03, 2020
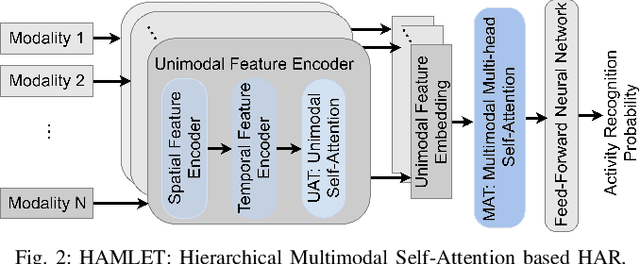
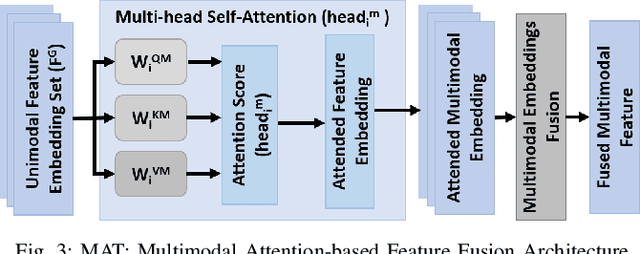
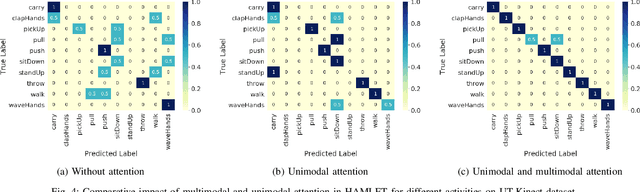
To fluently collaborate with people, robots need the ability to recognize human activities accurately. Although modern robots are equipped with various sensors, robust human activity recognition (HAR) still remains a challenging task for robots due to difficulties related to multimodal data fusion. To address these challenges, in this work, we introduce a deep neural network-based multimodal HAR algorithm, HAMLET. HAMLET incorporates a hierarchical architecture, where the lower layer encodes spatio-temporal features from unimodal data by adopting a multi-head self-attention mechanism. We develop a novel multimodal attention mechanism for disentangling and fusing the salient unimodal features to compute the multimodal features in the upper layer. Finally, multimodal features are used in a fully connect neural-network to recognize human activities. We evaluated our algorithm by comparing its performance to several state-of-the-art activity recognition algorithms on three human activity datasets. The results suggest that HAMLET outperformed all other evaluated baselines across all datasets and metrics tested, with the highest top-1 accuracy of 95.12% and 97.45% on the UTD-MHAD [1] and the UT-Kinect [2] datasets respectively, and F1-score of 81.52% on the UCSD-MIT [3] dataset. We further visualize the unimodal and multimodal attention maps, which provide us with a tool to interpret the impact of attention mechanisms concerning HAR.