 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPASS: A Formal Framework and Aggregate Dataset for Generalized Surgical Procedure Modeling
Paper and Code
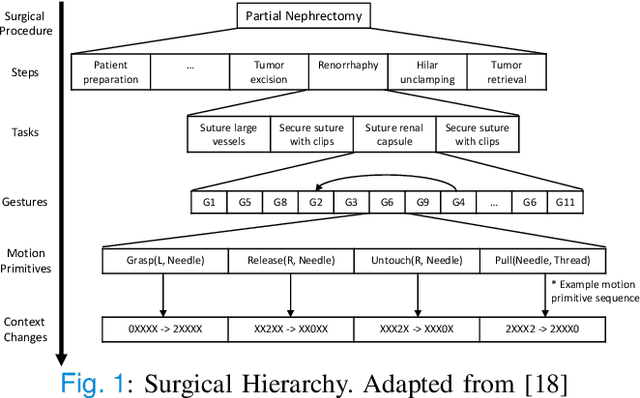
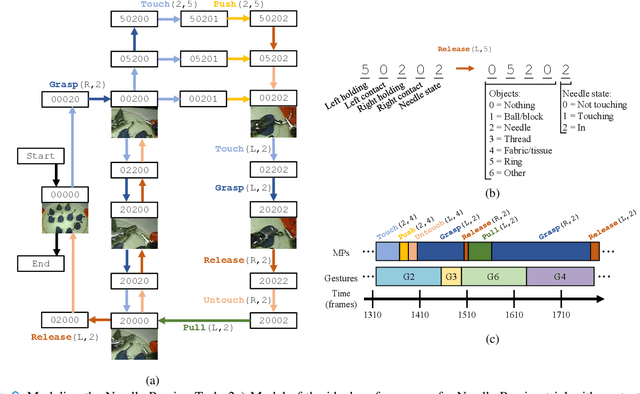


Objective: We propose a formal framework for modeling surgical tasks using a unified set of motion primitives (MPs) as the basic surgical actions to enable more objective labeling and aggregation of different datasets and training generalized models for surgical action recognition. Methods: We use our framework to create the COntext and Motion Primitive Aggregate Surgical Set (COMPASS), including six dry-lab surgical tasks from three publicly-available datasets (JIGSAWS, DESK, and ROSMA) with kinematic and video data and context and MP labels. Methods for labeling surgical context and automatic translation to MPs are presented. We propose the Leave-One-Task-Out (LOTO) cross validation method to evaluate a model's ability to generalize to an unseen task. Results: Our context labeling method achieves near-perfect agreement between consensus labels from crowd-sourcing and expert surgeons. Segmentation of tasks to MPs enables the generation of separate left and right transcripts and significantly improves LOTO performance. We find that MP segmentation models perform best if trained on tasks with the same context and/or tasks from the same dataset. Conclusion: The proposed framework enables high-quality labeling of surgical data based on context and fine-grained MPs. Modeling surgical tasks with MPs enables the aggregation of different datasets for training action recognition models that can generalize better to unseen tasks than models trained at the gesture level. Significance: Our formal framework and aggregate dataset can support the development of models and algorithms for surgical process analysis, skill assessment, error detection, and autonomy.