 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Scene Segmentation with Memory Network for Runtime Surgical Context Inference
Aug 24, 2023Surgical context inference has recently garnered significant attention in robot-assisted surgery as it can facilitate workflow analysis, skill assessment, and error detection. However, runtime context inference is challenging since it requires timely and accurate detection of the interactions among the tools and objects in the surgical scene based on the segmentation of video data. On the other hand, existing state-of-the-art video segmentation methods are often biased against infrequent classes and fail to provide temporal consistency for segmented masks. This can negatively impact the context inference and accurate detection of critical states. In this study, we propose a solution to these challenges using a Space Time Correspondence Network (STCN). STCN is a memory network that performs binary segmentation and minimizes the effects of class imbalance. The use of a memory bank in STCN allows for the utilization of past image and segmentation information, thereby ensuring consistency of the masks. Our experiments using the publicly available JIGSAWS dataset demonstrate that STCN achieves superior segmentation performance for objects that are difficult to segment, such as needle and thread, and improves context inference compared to the state-of-the-art. We also demonstrate that segmentation and context inference can be performed at runtime without compromising performance.
Evaluating the Task Generalization of Temporal Convolutional Networks for Surgical Gesture and Motion Recognition using Kinematic Data
Jun 28, 2023



Fine-grained activity recognition enables explainable analysis of procedures for skill assessment, autonomy, and error detection in robot-assisted surgery. However, existing recognition models suffer from the limited availability of annotated datasets with both kinematic and video data and an inability to generalize to unseen subjects and tasks. Kinematic data from the surgical robot is particularly critical for safety monitoring and autonomy, as it is unaffected by common camera issues such as occlusions and lens contamination. We leverage an aggregated dataset of six dry-lab surgical tasks from a total of 28 subjects to train activity recognition models at the gesture and motion primitive (MP) levels and for separate robotic arms using only kinematic data. The models are evaluated using the LOUO (Leave-One-User-Out) and our proposed LOTO (Leave-One-Task-Out) cross validation methods to assess their ability to generalize to unseen users and tasks respectively. Gesture recognition models achieve higher accuracies and edit scores than MP recognition models. But, using MPs enables the training of models that can generalize better to unseen tasks. Also, higher MP recognition accuracy can be achieved by training separate models for the left and right robot arms. For task-generalization, MP recognition models perform best if trained on similar tasks and/or tasks from the same dataset.
Towards Surgical Context Inference and Translation to Gestures
Mar 15, 2023



Manual labeling of gestures in robot-assisted surgery is labor intensive, prone to errors, and requires expertise or training. We propose a method for automated and explainable generation of gesture transcripts that leverages the abundance of data for image segmentation. Surgical context is detected using segmentation masks by examining the distances and intersections between the tools and objects. Next, context labels are translated into gesture transcripts using knowledge-based Finite State Machine (FSM) and data-driven Long Short Term Memory (LSTM) models. We evaluate the performance of each stage of our method by comparing the results with the ground truth segmentation masks, the consensus context labels, and the gesture labels in the JIGSAWS dataset. Our results show that our segmentation models achieve state-of-the-art performance in recognizing needle and thread in Suturing and we can automatically detect important surgical states with high agreement with crowd-sourced labels (e.g., contact between graspers and objects in Suturing). We also find that the FSM models are more robust to poor segmentation and labeling performance than LSTMs. Our proposed method can significantly shorten the gesture labeling process (~2.8 times).
COMPASS: A Formal Framework and Aggregate Dataset for Generalized Surgical Procedure Modeling
Sep 14, 2022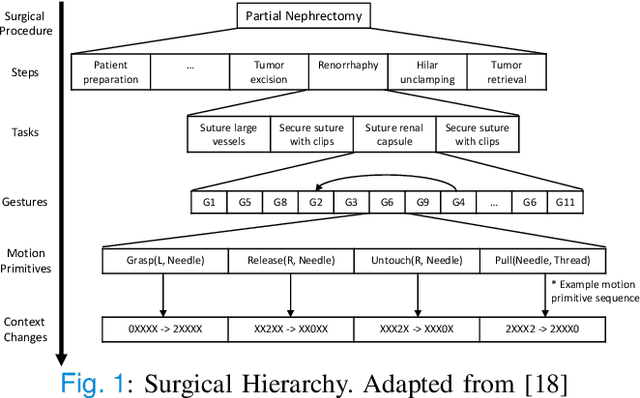
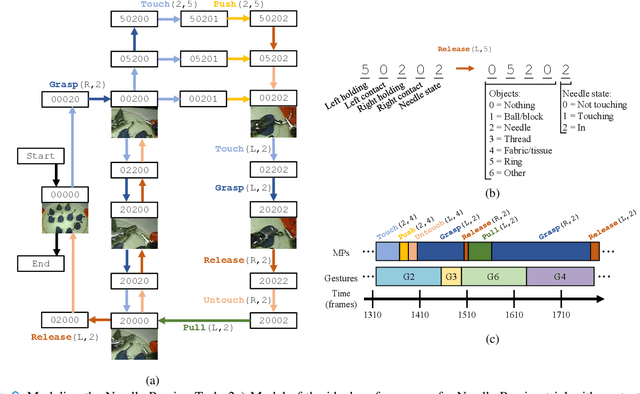


Objective: We propose a formal framework for modeling surgical tasks using a unified set of motion primitives (MPs) as the basic surgical actions to enable more objective labeling and aggregation of different datasets and training generalized models for surgical action recognition. Methods: We use our framework to create the COntext and Motion Primitive Aggregate Surgical Set (COMPASS), including six dry-lab surgical tasks from three publicly-available datasets (JIGSAWS, DESK, and ROSMA) with kinematic and video data and context and MP labels. Methods for labeling surgical context and automatic translation to MPs are presented. We propose the Leave-One-Task-Out (LOTO) cross validation method to evaluate a model's ability to generalize to an unseen task. Results: Our context labeling method achieves near-perfect agreement between consensus labels from crowd-sourcing and expert surgeons. Segmentation of tasks to MPs enables the generation of separate left and right transcripts and significantly improves LOTO performance. We find that MP segmentation models perform best if trained on tasks with the same context and/or tasks from the same dataset. Conclusion: The proposed framework enables high-quality labeling of surgical data based on context and fine-grained MPs. Modeling surgical tasks with MPs enables the aggregation of different datasets for training action recognition models that can generalize better to unseen tasks than models trained at the gesture level. Significance: Our formal framework and aggregate dataset can support the development of models and algorithms for surgical process analysis, skill assessment, error detection, and autonomy.