 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiDAS: A Multimodal Data Acquisition System and Dataset for Robot-Assisted Minimally Invasive Surgery
Feb 12, 2026Background: Robot-assisted minimally invasive surgery (RMIS) research increasingly relies on multimodal data, yet access to proprietary robot telemetry remains a major barrier. We introduce MiDAS, an open-source, platform-agnostic system enabling time-synchronized, non-invasive multimodal data acquisition across surgical robotic platforms. Methods: MiDAS integrates electromagnetic and RGB-D hand tracking, foot pedal sensing, and surgical video capturing without requiring proprietary robot interfaces. We validated MiDAS on the open-source Raven-II and the clinical da Vinci Xi by collecting multimodal datasets of peg transfer and hernia repair suturing tasks performed by surgical residents. Correlation analysis and downstream gesture recognition experiments were conducted. Results: External hand and foot sensing closely approximated internal robot kinematics and non-invasive motion signals achieved gesture recognition performance comparable to proprietary telemetry. Conclusion: MiDAS enables reproducible multimodal RMIS data collection and is released with annotated datasets, including the first multimodal dataset capturing hernia repair suturing on high-fidelity simulation models.
Multimodal Transformers for Real-Time Surgical Activity Prediction
Mar 11, 2024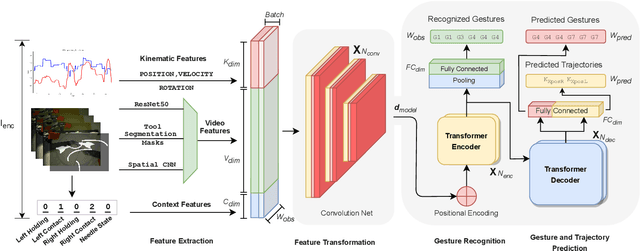

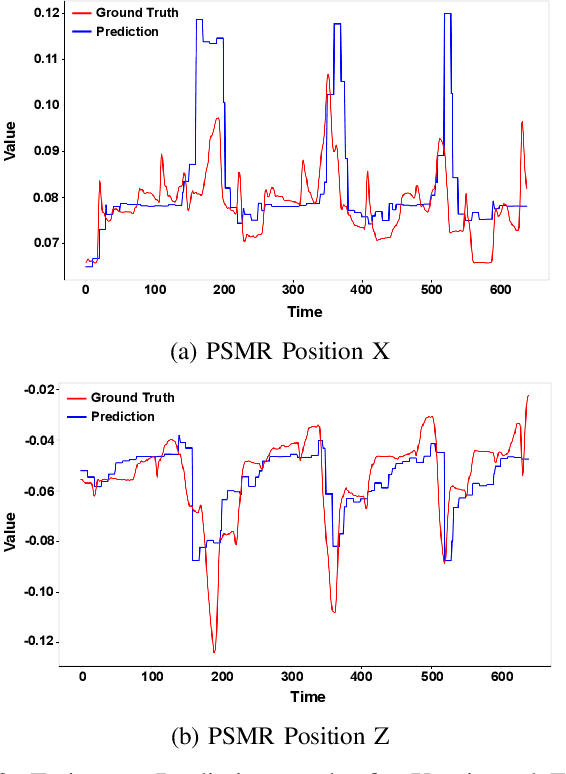
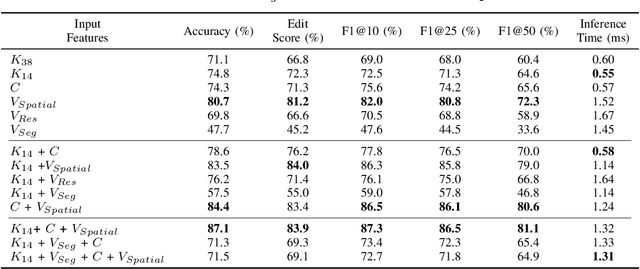
Real-time recognition and prediction of surgical activities are fundamental to advancing safety and autonomy in robot-assisted surgery. This paper presents a multimodal transformer architecture for real-time recognition and prediction of surgical gestures and trajectories based on short segments of kinematic and video data. We conduct an ablation study to evaluate the impact of fusing different input modalities and their representations on gesture recognition and prediction performance. We perform an end-to-end assessment of the proposed architecture using the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) dataset. Our model outperforms the state-of-the-art (SOTA) with 89.5\% accuracy for gesture prediction through effective fusion of kinematic features with spatial and contextual video features. It achieves the real-time performance of 1.1-1.3ms for processing a 1-second input window by relying on a computationally efficient model.