 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Keypoint Affordance Representation for Functional Dexterous Grasping
Feb 27, 2025



Functional dexterous grasping requires precise hand-object interaction, going beyond simple gripping. Existing affordance-based methods primarily predict coarse interaction regions and cannot directly constrain the grasping posture, leading to a disconnection between visual perception and manipulation. To address this issue, we propose a multi-keypoint affordance representation for functional dexterous grasping, which directly encodes task-driven grasp configurations by localizing functional contact points. Our method introduces Contact-guided Multi-Keypoint Affordance (CMKA), leveraging human grasping experience images for weak supervision combined with Large Vision Models for fine affordance feature extraction, achieving generalization while avoiding manual keypoint annotations. Additionally, we present a Keypoint-based Grasp matrix Transformation (KGT) method, ensuring spatial consistency between hand keypoints and object contact points, thus providing a direct link between visual perception and dexterous grasping actions. Experiments on public real-world FAH datasets, IsaacGym simulation, and challenging robotic tasks demonstrate that our method significantly improves affordance localization accuracy, grasp consistency, and generalization to unseen tools and tasks, bridging the gap between visual affordance learning and dexterous robotic manipulation. The source code and demo videos will be publicly available at https://github.com/PopeyePxx/MKA.
End-to-end Multi-Modal Multi-Task Vehicle Control for Self-Driving Cars with Visual Perception
Feb 02, 2018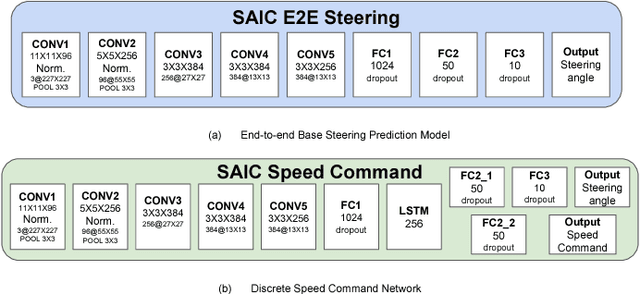



Convolutional Neural Networks (CNN) have been successfully applied to autonomous driving tasks, many in an end-to-end manner. Previous end-to-end steering control methods take an image or an image sequence as the input and directly predict the steering angle with CNN. Although single task learning on steering angles has reported good performances, the steering angle alone is not sufficient for vehicle control. In this work, we propose a multi-task learning framework to predict the steering angle and speed control simultaneously in an end-to-end manner. Since it is nontrivial to predict accurate speed values with only visual inputs, we first propose a network to predict discrete speed commands and steering angles with image sequences. Moreover, we propose a multi-modal multi-task network to predict speed values and steering angles by taking previous feedback speeds and visual recordings as inputs. Experiments are conducted on the public Udacity dataset and a newly collected SAIC dataset. Results show that the proposed model predicts steering angles and speed values accurately. Furthermore, we improve the failure data synthesis methods to solve the problem of error accumulation in real road tests.