 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMExplainer: Large Language Model based Bayesian Inference for Graph Explanation Generation
Paper and Code
Jul 23, 2024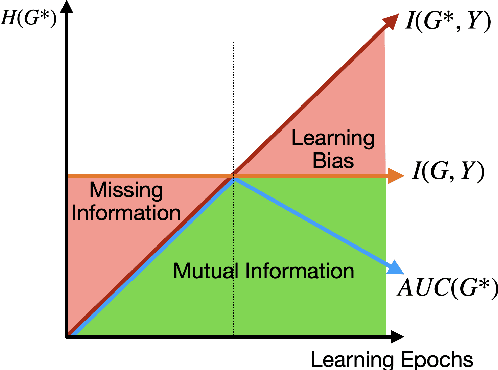
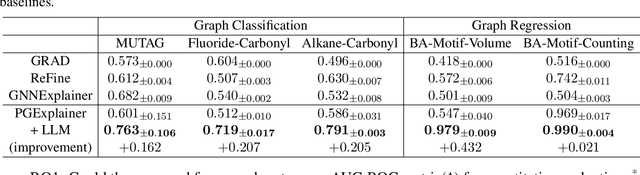
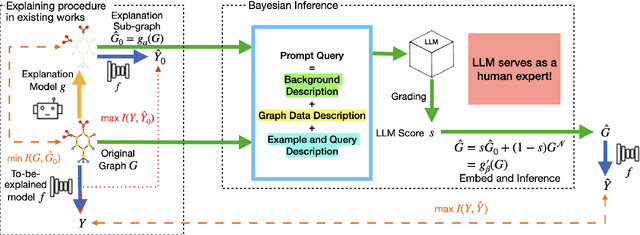

Recent studies seek to provide Graph Neural Network (GNN) interpretability via multiple unsupervised learning models. Due to the scarcity of datasets, current methods easily suffer from learning bias. To solve this problem, we embed a Large Language Model (LLM) as knowledge into the GNN explanation network to avoid the learning bias problem. We inject LLM as a Bayesian Inference (BI) module to mitigate learning bias. The efficacy of the BI module has been proven both theoretically and experimentally. We conduct experiments on both synthetic and real-world datasets. The innovation of our work lies in two parts: 1. We provide a novel view of the possibility of an LLM functioning as a Bayesian inference to improve the performance of existing algorithms; 2. We are the first to discuss the learning bias issues in the GNN explanation problem.