 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixLinear: Extreme Low Resource Multivariate Time Series Forecasting with 0.1K Parameters
Oct 02, 2024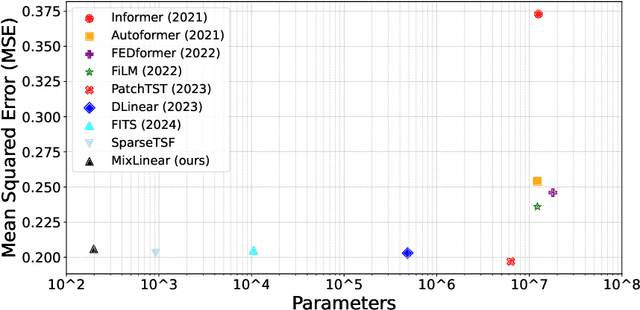
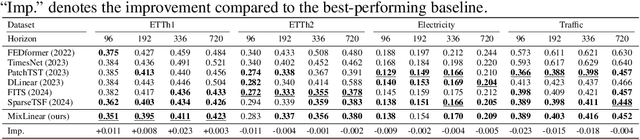
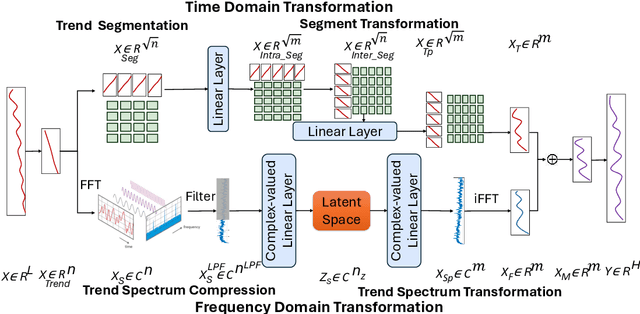
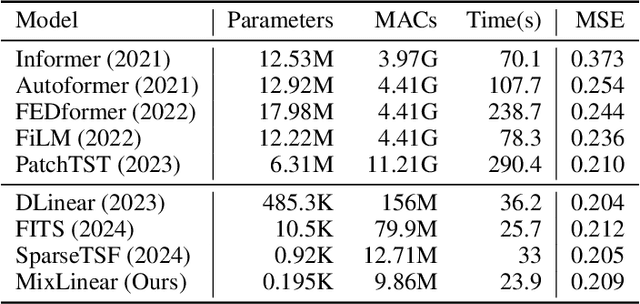
Recently, there has been a growing interest in Long-term Time Series Forecasting (LTSF), which involves predicting long-term future values by analyzing a large amount of historical time-series data to identify patterns and trends. There exist significant challenges in LTSF due to its complex temporal dependencies and high computational demands. Although Transformer-based models offer high forecasting accuracy, they are often too compute-intensive to be deployed on devices with hardware constraints. On the other hand, the linear models aim to reduce the computational overhead by employing either decomposition methods in the time domain or compact representations in the frequency domain. In this paper, we propose MixLinear, an ultra-lightweight multivariate time series forecasting model specifically designed for resource-constrained devices. MixLinear effectively captures both temporal and frequency domain features by modeling intra-segment and inter-segment variations in the time domain and extracting frequency variations from a low-dimensional latent space in the frequency domain. By reducing the parameter scale of a downsampled $n$-length input/output one-layer linear model from $O(n^2)$ to $O(n)$, MixLinear achieves efficient computation without sacrificing accuracy. Extensive evaluations with four benchmark datasets show that MixLinear attains forecasting performance comparable to, or surpassing, state-of-the-art models with significantly fewer parameters ($0.1K$), which makes it well-suited for deployment on devices with limited computational capacity.
MMFNet: Multi-Scale Frequency Masking Neural Network for Multivariate Time Series Forecasting
Oct 02, 2024Long-term Time Series Forecasting (LTSF) is critical for numerous real-world applications, such as electricity consumption planning, financial forecasting, and disease propagation analysis. LTSF requires capturing long-range dependencies between inputs and outputs, which poses significant challenges due to complex temporal dynamics and high computational demands. While linear models reduce model complexity by employing frequency domain decomposition, current approaches often assume stationarity and filter out high-frequency components that may contain crucial short-term fluctuations. In this paper, we introduce MMFNet, a novel model designed to enhance long-term multivariate forecasting by leveraging a multi-scale masked frequency decomposition approach. MMFNet captures fine, intermediate, and coarse-grained temporal patterns by converting time series into frequency segments at varying scales while employing a learnable mask to filter out irrelevant components adaptively. Extensive experimentation with benchmark datasets shows that MMFNet not only addresses the limitations of the existing methods but also consistently achieves good performance. Specifically, MMFNet achieves up to 6.0% reductions in the Mean Squared Error (MSE) compared to state-of-the-art models designed for multivariate forecasting tasks.
Parametric Augmentation for Time Series Contrastive Learning
Feb 16, 2024



Modern techniques like contrastive learning have been effectively used in many areas, including computer vision, natural language processing, and graph-structured data. Creating positive examples that assist the model in learning robust and discriminative representations is a crucial stage in contrastive learning approaches. Usually, preset human intuition directs the selection of relevant data augmentations. Due to patterns that are easily recognized by humans, this rule of thumb works well in the vision and language domains. However, it is impractical to visually inspect the temporal structures in time series. The diversity of time series augmentations at both the dataset and instance levels makes it difficult to choose meaningful augmentations on the fly. In this study, we address this gap by analyzing time series data augmentation using information theory and summarizing the most commonly adopted augmentations in a unified format. We then propose a contrastive learning framework with parametric augmentation, AutoTCL, which can be adaptively employed to support time series representation learning. The proposed approach is encoder-agnostic, allowing it to be seamlessly integrated with different backbone encoders. Experiments on univariate forecasting tasks demonstrate the highly competitive results of our method, with an average 6.5\% reduction in MSE and 4.7\% in MAE over the leading baselines. In classification tasks, AutoTCL achieves a $1.2\%$ increase in average accuracy.