 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartScan: An AI-based Interactive Framework for Automated Region Extraction from Satellite Images
Mar 31, 2025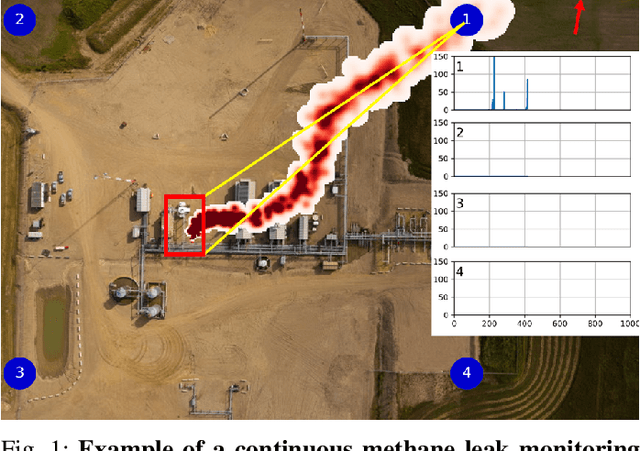
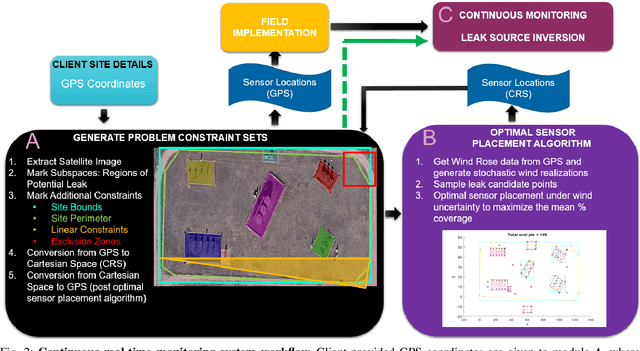

The deployment of a continuous methane monitoring system requires determining the optimal number and placement of fixed sensors. However, planning is labor-intensive, requiring extensive site setup and iteration to meet client restrictions. This challenge is amplified when evaluating multiple sites, limiting scalability. To address this, we introduce SmartScan, an AI framework that automates data extraction for optimal sensor placement. SmartScan identifies subspaces of interest from satellite images using an interactive tool to create facility-specific constraint sets efficiently. SmartScan leverages the Segment Anything Model (SAM), a prompt-based transformer for zero-shot segmentation, enabling subspace extraction without explicit training. It operates in two modes: (1) Data Curation Mode, where satellite images are processed to extract high-quality subspaces using an interactive prompting system for SAM, and (2) Autonomous Mode, where user-curated prompts train a deep learning network to replace manual prompting, fully automating subspace extraction. The interactive tool also serves for quality control, allowing users to refine AI-generated outputs and generate additional constraint sets as needed. With its AI-driven prompting mechanism, SmartScan delivers high-throughput, high-quality subspace extraction with minimal human intervention, enhancing scalability and efficiency. Notably, its adaptable design makes it suitable for extracting regions of interest from ultra-high-resolution satellite imagery across various domains.
SAMIC: Segment Anything with In-Context Spatial Prompt Engineering
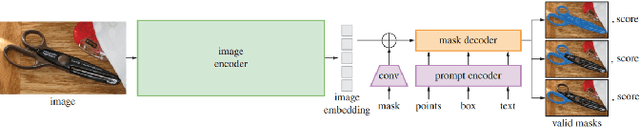
Dec 16, 2024Few-shot segmentation is the problem of learning to identify specific types of objects (e.g., airplanes) in images from a small set of labeled reference images. The current state of the art is driven by resource-intensive construction of models for every new domain-specific application. Such models must be trained on enormous labeled datasets of unrelated objects (e.g., cars, trains, animals) so that their ``knowledge'' can be transferred to new types of objects. In this paper, we show how to leverage existing vision foundation models (VFMs) to reduce the incremental cost of creating few-shot segmentation models for new domains. Specifically, we introduce SAMIC, a small network that learns how to prompt VFMs in order to segment new types of objects in domain-specific applications. SAMIC enables any task to be approached as a few-shot learning problem. At 2.6 million parameters, it is 94% smaller than the leading models (e.g., having ResNet 101 backbone with 45+ million parameters). Even using 1/5th of the training data provided by one-shot benchmarks, SAMIC is competitive with, or sets the state of the art, on a variety of few-shot and semantic segmentation datasets including COCO-$20^i$, Pascal-$5^i$, PerSeg, FSS-1000, and NWPU VHR-10.
Emotion Recognition from the perspective of Activity Recognition
Mar 24, 2024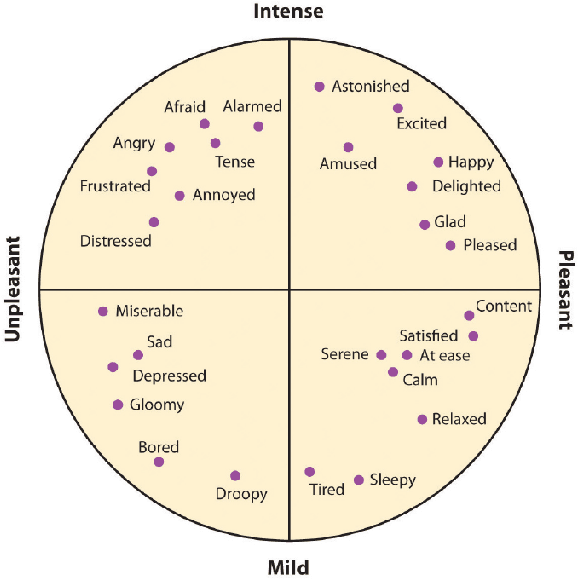
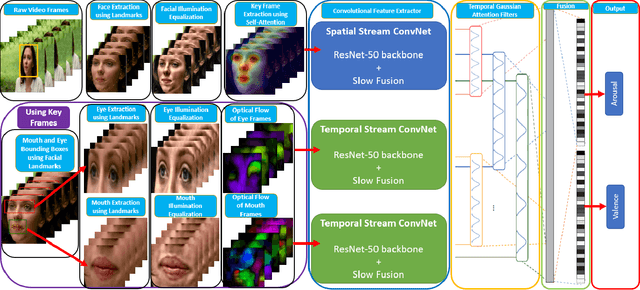
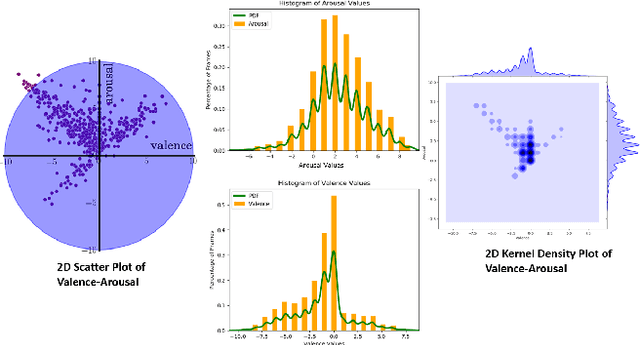
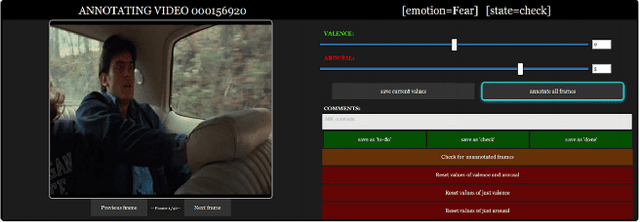
Applications of an efficient emotion recognition system can be found in several domains such as medicine, driver fatigue surveillance, social robotics, and human-computer interaction. Appraising human emotional states, behaviors, and reactions displayed in real-world settings can be accomplished using latent continuous dimensions. Continuous dimensional models of human affect, such as those based on valence and arousal are more accurate in describing a broad range of spontaneous everyday emotions than more traditional models of discrete stereotypical emotion categories (e.g. happiness, surprise). Most of the prior work on estimating valence and arousal considers laboratory settings and acted data. But, for emotion recognition systems to be deployed and integrated into real-world mobile and computing devices, we need to consider data collected in the world. Action recognition is a domain of Computer Vision that involves capturing complementary information on appearance from still frames and motion between frames. In this paper, we treat emotion recognition from the perspective of action recognition by exploring the application of deep learning architectures specifically designed for action recognition, for continuous affect recognition. We propose a novel three-stream end-to-end deep learning regression pipeline with an attention mechanism, which is an ensemble design based on sub-modules of multiple state-of-the-art action recognition systems. The pipeline constitutes a novel data pre-processing approach with a spatial self-attention mechanism to extract keyframes. The optical flow of high-attention regions of the face is extracted to capture temporal context. AFEW-VA in-the-wild dataset has been used to conduct comparative experiments. Quantitative analysis shows that the proposed model outperforms multiple standard baselines of both emotion recognition and action recognition models.
Estimating Uncertainty in Landslide Segmentation Models
Nov 18, 2023Landslides are a recurring, widespread hazard. Preparation and mitigation efforts can be aided by a high-quality, large-scale dataset that covers global at-risk areas. Such a dataset currently does not exist and is impossible to construct manually. Recent automated efforts focus on deep learning models for landslide segmentation (pixel labeling) from satellite imagery. However, it is also important to characterize the uncertainty or confidence levels of such segmentations. Accurate and robust uncertainty estimates can enable low-cost (in terms of manual labor) oversight of auto-generated landslide databases to resolve errors, identify hard negative examples, and increase the size of labeled training data. In this paper, we evaluate several methods for assessing pixel-level uncertainty of the segmentation. Three methods that do not require architectural changes were compared, including Pre-Threshold activations, Monte-Carlo Dropout and Test-Time Augmentation -- a method that measures the robustness of predictions in the face of data augmentation. Experimentally, the quality of the latter method was consistently higher than the others across a variety of models and metrics in our dataset.
ThreshNet: Segmentation Refinement Inspired by Region-Specific Thresholding
Nov 20, 2022We present ThreshNet, a post-processing method to refine the output of neural networks designed for binary segmentation tasks. ThreshNet uses the confidence map produced by a base network along with global and local patch information to significantly improve the performance of even state-of-the-art methods. Binary segmentation models typically convert confidence maps into predictions by thresholding the confidence scores at 0.5 (or some other fixed number). However, we observe that the best threshold is image-dependent and often even region-specific -- different parts of the image benefit from using different thresholds. Thus ThreshNet takes a trained segmentation model and learns to correct its predictions by using a memory-efficient post-processing architecture that incorporates region-specific thresholds as part of the training mechanism. Our experiments show that ThreshNet consistently improves over current the state-of-the-art methods in binary segmentation and saliency detection, typically by 3 to 5% in mIoU and mBA.
Foot Pressure from Video: A Deep Learning Approach to Predict Dynamics from Kinematics
Nov 30, 2018
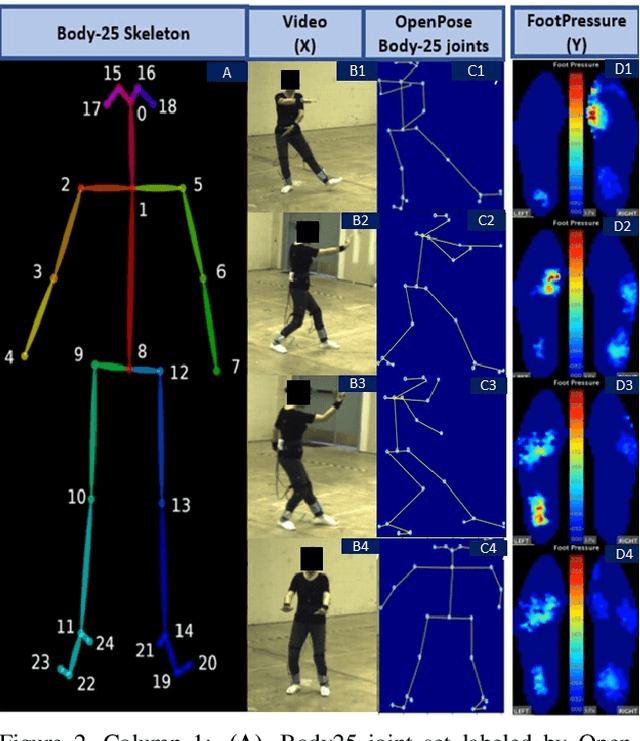
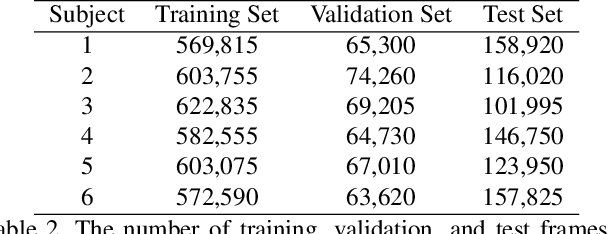
Human gait stability analysis is a key to understanding locomotion and control of body equilibrium, with numerous applications in the fields of Kinesiology, Medicine and Robotics. This work introduces a novel approach to learn dynamics of a human body from kinematics to aid stability analysis. We propose an end-to-end deep learning architecture to regress foot pressure from a human pose derived from video. This approach utilizes human Body-25 joints extracted from videos of subjects performing choreographed Taiji (Tai Chi) sequences using OpenPose estimation. The derived human pose data and corresponding foot pressure maps are used to train a convolutional neural network with residual architecture, termed PressNET, in an end-to-end fashion to predict the foot pressure corresponding to a given human pose. We create the largest dataset for simultaneous video and foot pressure on five subjects containing greater than 350k frames. We perform cross-subject evaluation with data from the five subjects on two versions of PressNET to evaluate the performance of our networks. KNearest Neighbors (KNN) is used to establish a baseline for comparisons and evaluation. We empirically show that PressNet significantly outperform KNN on all the splits.
Comparison of Reinforcement Learning algorithms applied to the Cart Pole problem
Oct 03, 2018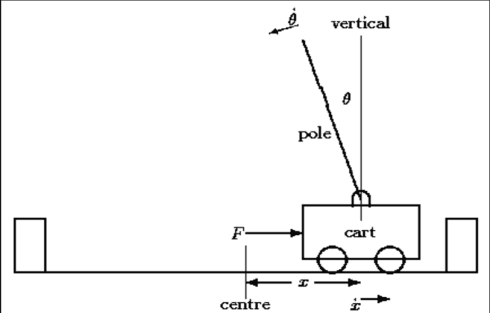
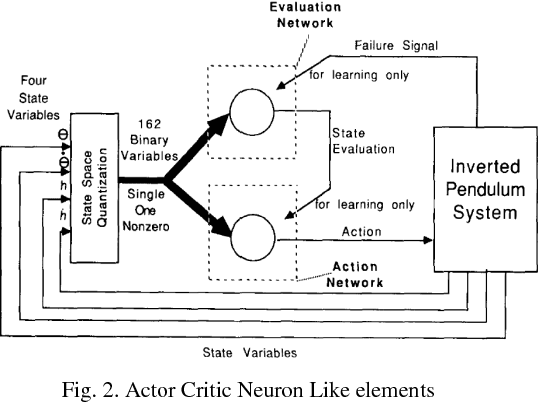

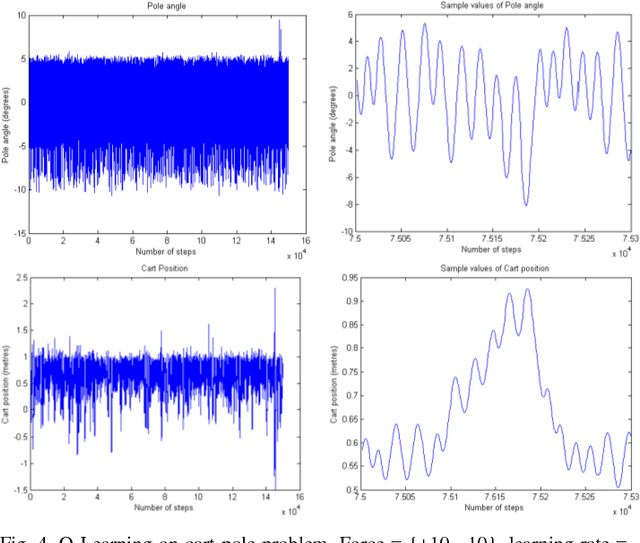
Designing optimal controllers continues to be challenging as systems are becoming complex and are inherently nonlinear. The principal advantage of reinforcement learning (RL) is its ability to learn from the interaction with the environment and provide optimal control strategy. In this paper, RL is explored in the context of control of the benchmark cartpole dynamical system with no prior knowledge of the dynamics. RL algorithms such as temporal-difference, policy gradient actor-critic, and value function approximation are compared in this context with the standard LQR solution. Further, we propose a novel approach to integrate RL and swing-up controllers.